Un generico sistema di Speech Recognition è progettato per eseguire 3 task:
- la cattura delle parole e delle frasi dette da un essere umano. Questo passaggio si concentra quindi solo sulla parte di workflow relativa all’acquisizione dei dati;
- l’applicazione del Natural Language Processing sui dati acquisiti, per riconoscere il contenuto del discorso;
- la sintesi delle parole riconosciute per aiutare una macchina a parlare lo stesso linguaggio.
Lo Speech Recognition può essere visto come un’estensione della pipeline di NLP e Machine Learning che avevamo costruito nel capitolo precedente. Ricordiamo che i segnali audio che i programmi dovranno processare vengono catturati con l’ausilio di un microfono e inviati al sistema.
Elaborazione del suono
Così come le immagini e i video, anche il suono si compone di segnali che gli umani percepiscono tramite gli organi di senso. Affinché una macchina possa elaborare informazioni come quelle uditive, bisogna memorizzare tali dati sotto forma di segnali digitali e analizzarli con dei programmi ad hoc. Sono due i processi che servono a convertire un segnale analogico in digitale:
- Campionamento: è la procedura usata per convertire un segnale s(t) che varia in funzione del tempo in una progressione x(n) discreta di numeri reali. Il termine che definisce l’intervallo tra due campioni consecutivi è il periodo di campionamento Ts. L’inverso del periodo di campionamento è detto frequenza di campionamento (fs=1/Ts). Tipiche frequenze di campionamento sono 8 KHz, 16 KHz e 44.1 KHz. Un rate di campionamento di 1 Hz significa che viene campionato un campione al secondo, per cui rate elevati indicano una migliore qualità del segnale.
- Quantizazzione: è il processo di sostituzione dei numeri reali del campionamento in valori approssimati definiti in un certo intervallo di bit. Solitamente si usano 16 bit per rappresentare un esempio quantizzato. Inoltre, gli audio grezzi hanno un intervallo di segnale tra –215 e 215, sebbene questi valori vengano standardizzati nell’intervallo (–1,1) durante l’analisi, per semplificare il training e la validazione dei modelli. La risoluzione dei campioni, comunque, si misura sempre in bit/sample.
Costruire un processo di Speech Recognition
In termini di IA, lo Speech Recognition viene di rado chiamato anche Automatic Speech Recognition (ASR) ed è il fulcro del processo che lavora con input parlati forniti da esseri umani. Senza l’ASR, l’interazione tra umani e robot non sarebbe possibile. Esistono numerose criticità da considerare durante la costruzione di sistemi di Speech Recognition, come:
- Size del vocabolario: cioè il numero di parole, o frasi, processabili da un algoritmo. La dimensione del vocabolario influisce molto sulla complessità e sulle performance del modello di speech recognition. Un vocabolario di piccole dimensioni può essere ad esempio quello di in un sistema per menù, che avrebbe circa 200 parole. Un vocabolario medio, invece, conterrebbe circa un migliaio di parole, mentre un vocabolario da 10.000 termini in su è considerato di grande dimensioni.
- Caratteristiche del canale: il canale è il mezzo attraverso il quale vengono trasmessi i segnali audio e costituisce un ulteriore fattore importante nella costruzione dei modelli. Ad esempio, la voce umana diretta può essere registrata in piena frequenza e con elevata ampiezza di banda, mentre l’audio di una conversazione telefonica avrebbe una banda più stretta e un range di frequenza limitato, complicando il processo di analisi.
- Stile del parlato: trovare due conversazioni tra umani dal suono identico è praticamente impossibile, questo perché ognuno ha un proprio tono di voce e una propria cadenza. Anche nell’ambito della stessa lingua, lo stile del discorso differisce molto tra le persone. Inoltre, un discorso in stile formale è più semplice da analizzare rispetto a uno informale.
- Presenza di rumore: il rumore esterno è presente quasi in tutti gli ambienti e gioca un ruolo decisivo nella qualità del suono. Livelli di rumore elevati, intorno ai 30 bB, sono considerati complicati da trattare, suoni in un intervallo tra 10–30 dB creano disturbi moderati, mentre al di sotto dei 10 dB le analisi non vengono compromesse in maniera significativa.
- Qualità del microfono: usare un microfono è l’unico modo per acquisire l’input per gli algoritmi di speech recognition. Infatti, anche la qualità di questo strumento è un fattore importante che può procurare difficoltà durante il processo di speech recognition.
Nonostante la presenza di tali difficoltà, si può attenuare il loro effetto grazie a diverse tecniche di pre–processing. Nella prossima sezione impareremo di più sulla costruzione di modelli di riconoscimento vocale.
.png.aspx;)
Iniziamo a vedere come elaborare un segnale sonoro letto da un file audio. Esistono diverse fonti da cui poter scaricare file su cui fare esperimenti. Vedremo anche come implementare un metodo che registra l’audio da processare con Python direttamente dal microfono.
Step 1: Leggere un file audio
File I/O in Python (scipy.io): SciPy dispone di vari metodi per effettuare operazioni coi file in Python. La parte di I/O include metodi come read(filename[, mmap]) e write(filename, rate, data), usati per leggere da un file .wav e scrivere il file sotto forma di NumPy array. Useremo questi metodi per operare sul nostro file.
Lo step iniziale di un algoritmo di speech recognition è la creazione di un sistema in grado di leggere file audio (.wav, .mp3, ecc) e di capirne le informazioni presenti all’interno. Python dispone di librerie per leggere e interpretare questi file. Lo scopo di questo step è visualizzare i segnali audio come punti strutturati.
- Registrazione: Una registrazione è il file fornito in input all’algoritmo, il quale ne analizza il contenuto e costruisce un modello di speech recognition. Questo record può essere un file in memoria oppure può essere registrato live e Python permette di lavorare con entrambi i casi.
- Campionamento: Tutti i segnali di una registrazione vengono salvati in forma digitale. I digit sono difficili da elaborare per un software, dal momento che le macchine lavorano con input numerici. Il campionamento è infatti la tecnica usata per convertire i segnali digitali in segnali numerici discreti. Il campionamento viene fatto a una certa frequenza e genera segnali numerici. La scelta dei livelli di frequenza dipende dalla percezione del suono, ad esempio si sceglie una frequenza elevata se percepiamo l’audio come continuo.
# Fonte dell’audio: Sample Audio File Download
# Importiamo le librerie necessarie
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
# Leggiamo il file audio e verifichiamo la dimensione del segnale e la frequenza di campionamento
# Forniamo il path del file
freq_sample, sig_audio = wavfile.read("Welcome.wav")
# Parametri di output: dimensione del segnale, frequenza di campionamento e durata
print('\nShape of Signal:', sig_audio.shape)
print('Signal Datatype:', sig_audio.dtype)
print('Signal duration:', round(sig_audio.shape[0] / float(freq_sample), 2), 'seconds')
>>> Shape of Signal: (645632,)
>>> Signal Datatype: int16
>>> Signal duration: 40.35 seconds
# Normalizziamo i valori del segnale
pow_audio_signal = sig_audio / np.power(2, 15)
# Estraiamo i primi 100 valori
pow_audio_signal = pow_audio_signal [:100]
time_axis = 1000 * np.arange(0, len(pow_audio_signal), 1) / float(freq_sample)
# Visualizziamo il segnale
plt.plot(time_axis, pow_audio_signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()
>>>
.png.aspx;) # Questa è la rappresentazione dell’ampiezza suono rispetto alla durata della registrazione.
# Abbiamo estratto con successo dati numerici a partire da un file audio in formato .wav .
# Questa è la rappresentazione dell’ampiezza suono rispetto alla durata della registrazione.
# Abbiamo estratto con successo dati numerici a partire da un file audio in formato .wav .
Una volta letto il contenuto del file, il passo successivo è la manipolazione dei segnali audio osservati. Una trasformazione importante è quella della frequenza, che serve a saperne di più sull’audio che si sta analizzando. Nella prossima sezione vedremo come effettuare una trasformazione di frequenza.
Step 2: Trasformare le frequenze audio
Rappresentazione basata sul tempo
La rappresentazione di un file audio può essere fatta innanzitutto nel dominio del tempo. Questa rappresentazione evidenzia l’intensità (o volume o ampiezza) dell’onda sonora nel dominio temporale. Parti con intensità pari a 0 indicano istanti di silenzio. In termini di ingegneria del suono, intensità=0 è il suono delle particelle d'aria ferme o in movimento quando nell’ambiente non è presente nessun altro suono. L’analisi di questa rappresentazione però non è molto fruttuosa poiché si concentra solo sul volume dell'audio.
Rappresentazione basata sulla frequenza
Un modo migliore per capire un segnale audio è osservarlo nel dominio della frequenza. Questo tipo di rappresentazione ci fornisce dettagli sulla presenza di variazioni di frequenza all’interno del segnale. Il concetto matematico usato nella conversione di un segnale continuo dal dominio del tempo a quello delle frequenze è la Trasformata di Fourier. Useremo la trasformata di Fourier (FT) in Python per convertire i segnali audio in rappresentazioni basate sulla frequenza.
Trasformata di Fourier in Python
I segnali audio sono tutti composti da un insieme di tante onde di frequenza, che viaggiano insieme per creare una perturbazione nel mezzo di trasmissione, che può essere, ad esempio, una stanza. Per catturare il suono è fondamentale catturare l’intensità di frequenza generata nello spazio da queste onde. La trasformata di Fourier è un concetto matematico che serve a decomporre un segnale estraendo le singole frequenze che lo compongono. Questo è fondamentale per comprendere quali sono le frequenze che si combinano insieme nel formare i suoni che ascoltiamo. La trasformata di Fourier (FT) fornisce tutte le frequenze presenti nel segnale e mostra anche l'ampiezza di ciascuna frequenza. Nella sezione di codice che segue, trasformeremo il file welcome.wav nel suo dominio di frequenza. Rappresenteremo anche le singole frequenze e la loro ampiezza.
.gif.aspx;)
La funzione np.fft.fft di NumPy ci permette di calcolare una trasformata di Fourier discreta monodimensionale. La funzione usa l’algoritmo Fast Fourier Transform (FFT) per convertire una sequenza data in una trasformata di Fourier discreta (DFT). Nel file che stiamo elaborando, abbiamo una sequenza di ampiezze tratte da un file audio che erano state originariamente campionate da un segnale continuo. Useremo la funzione FFT per convertire questo dominio del tempo in un segnale discreto nel dominio della frequenza.
# Caratterizzazione del segnale dal file di input
# Useremo la trasformata di Fourier per convertire i segnali in una distribuzione sul dominio di frequenza
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
freq_sample, sig_audio = wavfile.read("Welcome.wav")
print('\nShape of the Signal:', sig_audio.shape)
print('Signal Datatype:', sig_audio.dtype)
print('Signal duration:', round(sig_audio.shape[0] / float(freq_sample), 2), 'seconds')
>>> Shape of the Signal: (645632,)
>>> Signal Datatype: int16
>>> Signal duration: 40.35 seconds
# Normalizziamo
sig_audio = sig_audio / np.power(2, 15)
# Estraiamo la lunghezza e la metà della lunghezza del segnale da immettere nella trasformata di Fourier
sig_length = len(sig_audio)
half_length = np.ceil((sig_length + 1) / 2.0).astype(np.int)
# Useremo la trasformata di Fourier per generare il dominio di frequenza del segnale
signal_freq = np.fft.fft(sig_audio)
# Normalizziamo il dominio e eleviamolo al quadrato
signal_freq = abs(signal_freq[0:half_length]) / sig_length
signal_freq **= 2
transform_len = len(signal_freq)
# Il segnale trasformato ora necessita di essere "aggiustato" per i casi pari e dispari
if sig_length % 2:
signal_freq[1:transform_len] *= 2
else:
signal_freq[1:transform_len–1] *= 2
# Estraiamo la potenza in decibel del segnale
exp_signal = 10 * np.log10(signal_freq)
x_axis = np.arange(0, half_length, 1) * (freq_sample / sig_length) / 1000.0
plt.figure()
plt.plot(x_axis, exp_signal, color='green', linewidth=1)
plt.xlabel('Frequency Representation (kHz)')
plt.ylabel('Power of Signal (dB)')
plt.show()
>>>
.png.aspx;)
Come si vede, i segnali audio possono anche essere suddivisi in una distribuzione di frequenza che mostra la potenza (o ampiezza) di ciascuna frequenza ottenuta dal file audio. Questo è importante per avere una visione della distribuzione delle frequenza del suono di input. Nella prossima sezione vedremo come i segnali monotoni e le loro singole ampiezze aiutano a costruire i segnali e come la distribuzione delle frequenze può aiutare a creare filtri per i dati. Questi filtri aiutano a delimitare le distribuzioni di frequenza con dei limiti ben definiti.
Importanza dei segnali audio monotoni
Prima di proseguire, dobbiamo capire la differenza tra segnali stereo e segnali monotoni. I suoni generati in qualsiasi ambiente sono sempre suoni stereo. Un segnale monotono invece è un segnale che viene prodotto su un solo canale ed è più facile da analizzare.
Dal punto di vista fisico, il suono è una vibrazione in movimento. In altre parole, le onde che si muovono in un mezzo isolato come l'aria sono l'origine del suono. Le onde sonore emettono e trasferiscono energia tra le particelle d’aria fino a raggiungere una destinazione (ad esempio, le nostre orecchie). Due attributi fondamentali che definiscono il suono sono l'ampiezza, che si concentra sull'intensità/volume dell'onda sonora, e la frequenza, che misura le vibrazioni dell'onda nell’unità di tempo. Quindi, in teoria, non si può creare nessun suono senza il movimento di onde.
Inoltre, dato che il suono necessita un mezzo di trasmissione, i parametri come potenza e frequenza dipenderanno sempre da fattori esterni come il rumore e non possono quindi essere costruiti altrimenti. Tuttavia, durante il riconoscimento vocale e l’analisi dei suoni, potrebbe servire che alcuni segnali abbiano una struttura predefinita. Python ci consente di creare segnali audio e di scriverli in un file in formato .wav. Nella prossima sezione, andreamo a creare un segnale audio con alcuni parametri predefiniti.
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import write
# Specifichiamo il file di output su cui salvare i dati
output_file = 'generated_signal_audio.wav'
# Durata in secondi, Frequenza di campionamento in Hz
sig_duration = 8
sig_frequency_sampling = 74100
sig_frequency_tone = 802
sig_min_val = –5 * np.pi
sig_max_val = 5 * np.pi
# Generazione del segnale audio
temp_signal = np.linspace(sig_min_val, sig_max_val, sig_duration * sig_frequency_sampling)
temp_audio_signal = np.sin(2 * np.pi * sig_frequency_tone * temp_signal)
# La funzione write() crea e scrive su file un segnale sonoro basato su frequenza
write(output_file, sig_frequency_sampling, temp_audio_signal)
sig_audio = temp_audio_signal[:100]
def_time_axis = 1000 * np.arange(0, len(sig_audio), 1) / float(sig_frequency_sampling)
plt.plot(def_time_axis, sig_audio, color='green')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Sound Amplitude')
plt.title('Audio Signal Generation')
plt.show()
>>>
.png.aspx;)
La generazione di segnali audio è un task importante di supporto al processo di analisi, per esempio nel momento in cui bisogna generare nuovi segnali di test. La caratteristica più importante in questo caso è che tutti i parametri della creazione del segnale possono essere controllati e scelti dall’utente.
Step 3: Estrarre le feature dal discorso
Una volta trasferito il segnale dal dominio del tempo a quello delle frequenze, lo step successivo è convertire i dati ottenuti in un vettore di feature utile. Andiamo quindi a parlare di MFCC.
Mel Frequency Cepstral Coefficient (MFCC)
La tecnica MFCC è stata sviluppata per l’estrazione delle feature da un segnale audio. Usa la scala MEL per dividere le bande di frequenza del segnale audio ed estrarre i coefficienti da ognuna delle bande, in modo da creare una separazione tra le diverse frequenze. Per effettuare quest’operazione, MFCC usa la trasformata discreta del coseno (DCT). La scala MEL è stata stabilita sulla percezione umana del suono, ad esempio, su come il cervello umano processa i segnali uditivi e come distingue le varie frequenze. Vediamo come è formata la scala MEL.
- Percezione della voce umana: Un umano adulto ha una capacità uditiva di base che va da 85 Hz a 255 Hz, con un ulteriore distinzione tra i sessi (85 Hz–180 Hz per gli uomini e 165 Hz–255 Hz per le donne). Al di sopra di queste frequenze di base, l’orecchio elabora anche le armoniche, che sono delle ripetizioni della frequenza fondamentale. Sono semplici moltiplicatori, ad esempio, la seconda armonica di una frequenza di 100 Hz sarà di 200 Hz, la terza sarà di 300 Hz e così via. La gamma uditiva approssimativa per gli esseri umani è compresa tra 20 Hz e 20 KHz e anche questa percezione del suono non è lineare. Possiamo distinguere meglio i suoni a bassa frequenza rispetto ai suoni ad alta frequenza. Ad esempio, possiamo affermare chiaramente la differenza tra i segnali di 100Hz e 200Hz, ma non siamo in grado di distinguere tra 15000 Hz e 15100 Hz. Per generare toni di varie frequenze possiamo usare il codice di sopra o usare il tool Online Tone Generator.
- Scala MEL: La scala MEL è stata introdotta nel 1937 da Stevens, Volkmann e Newmann. Si tratta di una scala di tonalità (scala di segnali audio con vari livelli di tonalità) che viene giudicata dagli esseri umani sulla base di come percepiamo le distanze tra i suoni. In sostanza, è una scala basata sulla percezione umana dei suoni. Ad esempio, se siamo stati esposti a due sorgenti sonore distanti l'una dall'altra, il nostro cervello percepirà una distanza tra queste sorgenti, senza però vederle. Poiché la nostra percezione non è lineare, le distanze su questa scala aumentano con la frequenza.
- MEL–spaced Filterbank: Per calcolare la potenza di una banda di frequenza, il primo passo è distinguere le diverse bande di feature disponibili (si possono ottenere da MFCC). Una volta effettuate queste suddivisioni, utilizziamo i banchi di filtri per partizionare le frequenze. I banchi di filtri possono essere creati utilizzando qualsiasi frequenza specificata per le partizioni. L’intervallo tra i filtri all'interno di un banco cresce esponenzialmente all'aumentare della frequenza. Nel prossimo codice vedremo come separare le bande di frequenza.
La matematica di MFCC e dei Filter Banks
L'MFCC e la creazione dei banchi di filtri (Filter Banks) si motivano con natura dei segnali audio e sono influenzati dal modo in cui gli esseri umani percepiscono il suono. Tuttavia, questa elaborazione richiede anche molti calcoli matematici che stanno dietro l’implementazione. Python ci fornisce direttamente i metodi per creare i filtri e per eseguire la funzionalità MFCC sul suono, ma vogliamo anche dare uno sguardo alla matematica dietro queste operazioni. I tre modelli matematici discreti che entrano in questa elaborazione sono il Discrete Cosine Transform (DCT), che viene utilizzato per la scorrelazione dei coefficienti del banco dei filtri, definito anche come “imbiancamento” del suono, e le Gaussian Mixture Models – Hidden Markov Models (GMMs–HMMs), uno standard per gli algoritmi di Automatic Speech Recognition (ASR). Grazie al fatto che al giorno d'oggi i costi computazionali sono diminuiti grazie al Cloud Computing, per queste tecniche vengono utilizzati sistemi vocali di deep learning che sono meno suscettibili al rumore. Inoltre, bisogna notare che DCT è un algoritmo di trasformazione lineare e che quindi potrebbe escludere molti segnali utili, essendo il suono altamente non lineare.
pip install python_speech_features
# Importiamo le librerie necessarie
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbank
sampling_freq, sig_audio = wavfile.read("Welcome.wav")
# Per l’analisi prendiamo i primi 15mila esempi del segnale originale
sig_audio = sig_audio[:15000]
# Usiamo MFCC per estrarre le feature dal segnale
mfcc_feat = mfcc(sig_audio, sampling_freq)
print('\nMFCC Parameters\nWindow Count =', mfcc_feat.shape[0])
print('Individual Feature Length =', mfcc_feat.shape[1])
>>> MFCC Parameters
>>> Window Count = 13
>>> Individual Feature Length = 93
mfcc_feat = mfcc_feat.T
plt.matshow(mfcc_feat)
plt.title('MFCC Features')
>>>
.png.aspx;) # Le prime line gialle orizzontali sotto ogni segmento sono la frequenza fondamentale e il suo massimo. Sotto la linea gialla ci sono le armoniche, che condividono tra loro la stessa distanza in termini di frequenza
# Generazione delle feature del banco dei filtri
fb_feat = logfbank(sig_audio, sampling_freq)
print('\nFilter bank\nWindow Count =', fb_feat.shape[0])
print('Individual Feature Length =', fb_feat.shape[1])
>>> Filter bank
>>> Window Count = 93
>>> Individual Feature Length = 26
fb_feat = fb_feat.T
plt.matshow(fb_feat)
plt.title('Features from Filter bank')
plt.show()
>>>
# Le prime line gialle orizzontali sotto ogni segmento sono la frequenza fondamentale e il suo massimo. Sotto la linea gialla ci sono le armoniche, che condividono tra loro la stessa distanza in termini di frequenza
# Generazione delle feature del banco dei filtri
fb_feat = logfbank(sig_audio, sampling_freq)
print('\nFilter bank\nWindow Count =', fb_feat.shape[0])
print('Individual Feature Length =', fb_feat.shape[1])
>>> Filter bank
>>> Window Count = 93
>>> Individual Feature Length = 26
fb_feat = fb_feat.T
plt.matshow(fb_feat)
plt.title('Features from Filter bank')
plt.show()
>>>
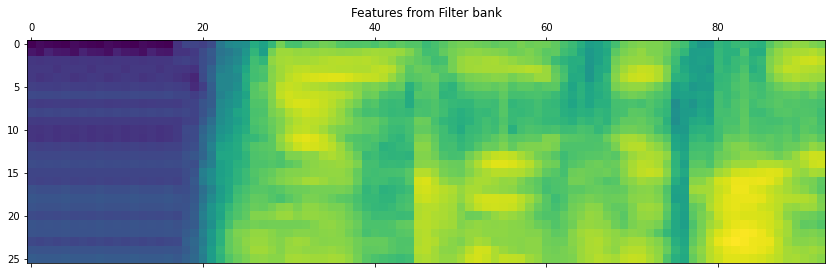
Se osserviamo le due distribuzioni è evidente che le distribuzioni dei suoni a bassa frequenza e ad alta frequenza sono nettamente separati nella seconda immagine. MFCC, insieme all'applicazione dei Filter Banks è risultato un buon algoritmo per separare i segnali ad alta e bassa frequenza. Ciò accelera il processo di analisi perché possiamo ritagliare i segnali sonori in due o più segmenti separati e analizzarli individualmente in base alle loro frequenze. Con ciò abbiamo completato la nostra analisi delle onde sonore. Lavorare con le parole è un'applicazione particolare della scienza cognitiva e esistono molti metodi e algoritmi da utilizzare. In questo capitolo abbiamo trattato le basi dell'ingegneria del suono e la comprensione dei segnali audio. Abbiamo anche visto come trasformare i file audio in un formato numerico che aiuta a costruire modelli su questi dati. Nella prossima sezione, utilizzeremo delle API open–source per comprendere il parlato e trascriverlo in testo. Questo sarà lo step finale della nostra pipeline di riconoscimento vocale.
Step 4: Riconoscere le parole parlate
Il riconoscimento vocale è il processo di comprensione della voce umana e di trascrizione in testo da parte di una macchina. Esistono diverse librerie disponibili per trasformare il parlato in testo, come Bing Speech, Google Speech, Houndify, IBM Speech to Text, ecc. Utilizzeremo la libreria Google Speech per la conversione.
Google Speech API
Per saperne di più sull’API Google Speech basta consultare la relativa pagina di Google Cloud sul text-to-speech e la pagina di PyPi sullo Speech Recognition. Tra le funzionalità principali dell'API di Google Speech c’è l'adattamento del discorso. Questo significa che l'API è in grado di capire il dominio del discorso. Ad esempio, valute, indirizzi, anni, sono tutte parole presenti nella conversione da discorso a testo. Esistono classi specifiche del dominio definite nell'algoritmo che riconoscono queste occorrenze nel discorso di input. L'API funziona sia con file in locale, preregistrati, sia con registrazioni live sul microfono nell'attuale ambiente di lavoro. Analizzeremo il discorso dal vivo attraverso l'input del microfono nella prossima sezione.
Usare i microfoni
La libreria open–source PyAudio consente di registrare direttamente l'audio tramite un microfono collegato al nostro ambiente e analizzarlo con Python in tempo reale. L'installazione di PyAudio varierà in base al sistema operativo.
- Classe
Microphone: un’istanza della classe Microphone può essere usata dal riconoscitore vocale per registrare direttamente l'audio all'interno della directory di lavoro. Per verificare se ci sono microfoni disponibili nel sistema, si usa il metodo statico list_microphone_names. Per utilizzare uno qualsiasi dei microfoni disponibili elencati, si usa il metodo device_index (mostreremo l’implementazione in seguito).
- Catturare l’input del microfono: la funzione
listen() viene usata per catturare l’input prelevato dal microfono. Tutti i segnali sonori ricevuti dal microfono vengono memorizzati nella variabile che chiama listen(). Questa funzione registra finché non rileva un segnale di silenzio, cioè di ampiezza 0. Riduzione del rumore ambientale: Qualsiasi ambiente è incline alla presenza di rumore ambientale che potrebbe ostacolare la registrazione. Per questo esiste un metodo della classe Recognizer, adjust_for_ambient_noise(), che aiuta a rimuovere automaticamente il rumore ambientale dai suoni registrati.
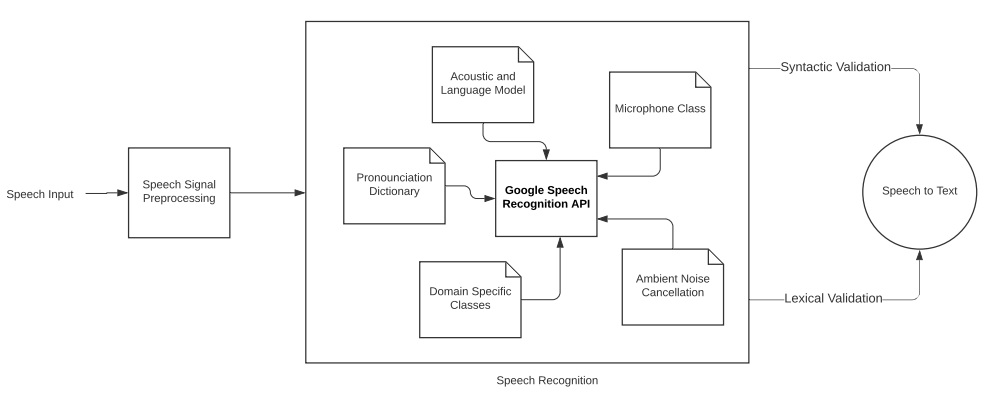
- Riconoscimento del suono: l’immagine seguente mostra la parte di flusso di lavoro dello Speech Recognition successiva all’elaborazione dei segnali, in cui si usano delle API per effettuare correzioni semantiche e sintattiche, comprendere il dominio del suono e il linguaggio parlato, e infine per produrre la conversione del discorso in testo. In particolare, si vede come implementare l’API di Speech Recognition di Google con l’uso della classe
Microphone.
# Installiamo le classi SpeechRecognition e pipwin per lavorare con la classe Recognizer()
pip install SpeechRecognition
pip install pipwin
# In seguito sono riportati alcuni link per maggiori dettagli sulla classe PyAudio che useremo per leggere direttamente dal microfono nel nostro Jupyter Notebook
# https://anaconda.org/anaconda/pyaudio
# https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
# Per installare PyAudio esegui su linea di comando di Anaconda: conda install –c anaconda pyaudio
# L’installazione di PyAudio richiede Microsoft Visual C++ versione 14.0 o superiore.
# Lo si può ottenere da "Microsoft C++ Build Tools" : https://visualstudio.microsoft.com/visual–cpp–build–tools/
pip install pyaudio
import speech_recognition as speech_recog
# Creiamo un oggetto rec per memorizzare l’input
rec = speech_recog.Recognizer()
# Importiamo la classe microphone per verificare la disponibilità del dispositivo
mic_test = speech_recog.Microphone()
# Lista dei microfoni disponibili
speech_recog.Microphone.list_microphone_names()
>>>
['Microsoft Sound Mapper – Input',
'Microphone (Realtek(R) Audio)',
'Microsoft Sound Mapper – Output',
'Speakers (Realtek(R) Audio)',
'Stereo Mix (Realtek HD Audio Stereo input)',
'Headphones (Realtek HD Audio 2nd output)',
'Speakers 1 (Realtek HD Audio output with HAP)',
'Speakers 2 (Realtek HD Audio output with HAP)',
'PC Speaker (Realtek HD Audio output with HAP)',
'Mic in at front panel (black) (Mic in at front panel (black))',
'Microphone Array (Realtek HD Audio Mic input)']
# Useremo il modulo microphone per catturare la voce
# Scegliamo il secondo microfono per catturare l’audio per una durata di 3 secondi
with speech_recog.Microphone(device_index=1) as source:
rec.adjust_for_ambient_noise(source, duration=3)
print("Reach the Microphone and say something!")
audio = rec.listen(source)
>>> Reach the Microphone and say something!
# Usiamo la funzione recognize per trascrivere il parlato in testo
try:
print("I think you said: \n" + rec.recognize_google(audio))
except Exception as e:
print(e)
f
>>> I think you said:
>>> hello the weather is cold
# Abbiamo terminato il nostro progetto di speech recognition
Prossimamente
Lo Speech Recognition, o riconoscimento vocale, è un concetto di IA che consente alle macchine di ascoltare la voce umana e trascriverla in testo. Nonostante la sua natura complessa i casi d’uso che ruotano intorno allo speech recognition sono molteplici. Ad oggi gli algoritmi di Automatic Speech Recognition (ASR) sono impiegati in molti settori dall’aiutare gli utenti diversamente abili ad accedere a un computer ai sistemi di risposta automatica. Questo capitolo ha fornito una breve introduzione all’ingegneria del suono e ha mostrato alcune tecniche di manipolazione di base per la gestione degli audio. Anche se non abbiamo trattato l’argomento nel dettaglio questo tutorial aiuta a creare un quadro generale del funzionamento dell'analisi del parlato nel mondo dell'IA.
Nei prossimi capitoli ci concentreremo di più sulle scienze cognitive nell’ambito dell’IA e risolveremo alcuni problemi in questo campo, tratteremo:
- Scienza Cognitiva e Intelligenza Artificiale;
- Computer Vision in Python;
- Il mercato dell’AI.