Computer Vision, Algoritmi di Ricerca per l’Intelligenza Artificiale e Scienze cognitive
La Computer Vision è una classe di algoritmi di intelligenza artificiale (IA) che lavora sulle immagini, che possono essere in forma di figura o di video. Lavorare con le immagini è complesso, per questo esistono librerie, come OpenCV, per implementare la visione artificiale all’interno degli algoritmi di machine learning e di ricerca. Durante l’uso di OpenCV vedremo anche alcuni importanti algoritmi di ricerca e la loro implementazione nell’ambito della Computer Vision.
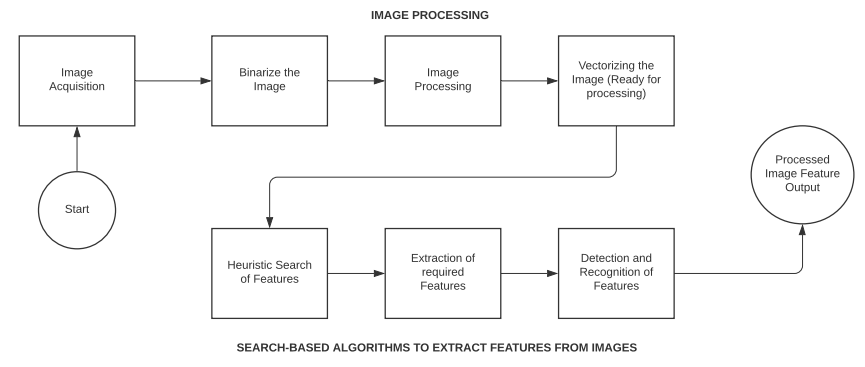
L’unico scopo dell’impiego degli algoritmi di ricerca è quello di ottimizzare l’esplorazione dello spazio dell’immagine, che è molto più diversificato rispetto a un semplice vettore di interi. L’Image Processing, invece, è una fase di elaborazione presente in ogni algoritmo di Computer Vision. Andiamo a vedere come questi algoritmi di ricerca ottimizzano l’elaborazione di video e immagini.
Algoritmi Euristici di Ricerca
Molti dei problemi di IA hanno natura esponenziale, cioè hanno più possibili soluzioni. Tipicamente, distinguere una soluzione errata da una corretta è difficile, e allo stesso tempo valutare tutte le possibili soluzioni è molto costoso. In questo viene in soccorso la ricerca euristica, che serve a restringere lo spazio di ricerca eliminando le soluzioni errate.
Il livello di intelligenza di una macchina si calcola spesso sulla base dell’efficienza con cui effettua la ricerca euristica. Allora perché abbiamo bisogno dell’euristica? Il primo motivo è la velocità, dal momento che l’obiettivo principale dei problemi di IA è produrre una risposta accettabile in poco tempo, più velocemente di altri algoritmi. In questi casi non è richiesta la soluzione ottima, ma piuttosto una soluzione approssimata che si può ottenere più velocemente.
La ricerca euristica ci permette di ridurre il grado esponenziale di un problema a una complessità polinomiale. La ricerca euristica è la soluzione migliore laddove gli algoritmi noti non funzionano o dove le ricerche non informate richiedono molto più tempo, data l’elevata dimensione dello spazio di ricerca.
Computer Vision e Ricerca Euristica
All’interno dei sistemi di calcolo, le immagini vengono memorizzate sotto forma di matrici di vettori. Questi vettori sono di tipo numerico. Gli algoritmi di ricerca sono cruciali nell’elaborazione delle immagini, in quanto anche un’immagine piccola è rappresentata un numero elevato di vettori. Gli algoritmi di ricerca aiutano a eliminare i vettori irrilevanti per gli algoritmi di riconoscimento. Vediamo alcuni algoritmi di ricerca importanti usati nella Computer Vision.
- Ricerca non informata: anche nota come strategia di controllo cieco o ricerca cieca. Il nome è determinato dal fatto che l’algoritmo è dotato solo della conoscenza relativa alla definizione del problema e non dispone di informazioni aggiuntive. Per questo, questo algoritmo di ricerca richiede di operare su tutto lo spazio di ricerca fino al ritrovamento di una soluzione. Tipiche tecniche di ricerca non informata sono la ricerca in profondità (Depth First Search – DFS) e la ricerca in ampiezza (Breadth First Search – BFS).
- Ricerca informata: una strategia di ricerca informata non è altro che una ricerca euristica. A questi algoritmi vengono infatti fornite informazioni aggiuntive che aiutano a velocizzare il processo di ricerca. Tali informazioni consentono all’algoritmo di scegliere i nodi migliori da visitare all’interno dello spazio di ricerca. Alcuni esempi sono la ricerca Best First e A* (A–star).
- Problemi di soddisfacimento di vincoli (CSP – Constraint Satisfaction Problems): letteralmente, un vincolo per un algoritmo è una restrizione o una limitazione. Nell’ambito dell’intelligenza artificiale, i problemi di soddisfacimento di vincoli sono problemi soggetti a determinate condizioni stringenti sotto le quali l’algoritmo deve operare. L’obiettivo principale dell’algoritmo, quindi, è non violare questi vincoli dati, ma lavorare all’interno di essi. In seguito, possiamo vedere un’implementazione del CSP.
# Risolviamo un problema CSP
# La maggior parte degli algoritmi di Computer Vision usano i CSP per costruire processi di apprendimento in ambienti che presentano tanti aspetti che sono immutabili durante l'analisi
# 1. Risolviamo l’equazione algebrica: [a*2=b]
# L’algoritmo deve ritornare il valore di a e b per un dominio definito
# Installiamo i pacchetti necessari
pip install python–constraint
>>>
Downloading python–constraint–1.4.0.tar.bz2 (18 kB)
Building wheels for collected packages: python–constraint
Building wheel for python–constraint (setup.py): started
Building wheel for python–constraint (setup.py): finished with status 'done'
Created wheel for python–constraint: filename=python_constraint–1.4.0–py2.py3–none–any.whl size=24086 sha256=a600eb3bc622b725c094af5097145dc850baf759c1b151d680b681de56020ebc
Successfully built python–constraint
Installing collected packages: python–constraint
Successfully installed python–constraint–1.4.0
# Importiamo la libreria constraint
from constraint import *
# Creiamo un nuovo oggetto Problem
object_prob = Problem()
# Ora definiamo le variabili in un intervallo tra 0 e 10
object_prob.addVariable('x', range(10))
object_prob.addVariable('y', range(10))
# Quindi specifichiamo i vincoli
object_prob.addConstraint(lambda x, y: x * 2 == y)
# Creiamo l’oggetto soluzione usando il metodo getSolutions()
object_solution = object_prob.getSolutions()
print (object_solution)
>>> [{'x': 4, 'y': 8}, {'x': 3, 'y': 6}, {'x': 2, 'y': 4}, {'x': 1, 'y': 2}, {'x': 0, 'y': 0}]
# 2. Implementazione del Magic Square Problem
# Una Magic Square è una griglia quadrata in cui i numeri di una riga, ogni colonna e le diagonali sono sommati di 1, detto Costante magica
def function_magic_square(input_matrix):
input_size = len(input_matrix[0])
input_sum = []
# Codice per il calcolo della griglia verticale
for col_num in range(input_size):
input_sum.append(sum(row_num[col_num] for row_num in input_matrix))
# Codice per il calcolo della griglia orizzontale
input_sum.extend([sum (lines) for lines in input_matrix])
# Porzione orizzontale
horizontal_result_l = 0
for i in range(0, input_size):
horizontal_result_l +=input_matrix[i][i]
input_sum.append(horizontal_result_l)
horizontal_result_r = 0
for i in range(input_size–1, –1, –1):
horizontal_result_r +=input_matrix[i][i]
input_sum.append(horizontal_result_r)
if len(set(input_sum))>1:
return False
return True
# Diamo in input una matrice e vediamo se è magica
print(function_magic_square([[4,2,1], [4,5,3], [3,2,9]]))
>>> False
# Ritorna falso perchè i vincoli non sono soddisfatti
# Proviamo con una vera Magic Square
print(function_magic_square([[2,7,6],[9,5,1],[4,3,8]]))
>>> True
In questa sezione abbiamo presentato la ricerca euristica, un’importante tecnica di ricerca ampiamente usata negli algoritmi di Intelligenza Artificiale. Nel segmento di codice abbiamo implementato un problema CSP in Python, ma comunque abbiamo visto che esistono moltissimi altri casi di ricerca euristica.
Euristica nelle Scienze Cognitive: Giudizio e Decision Making
I sistemi di calcolo cognitivo sono macchine che generano azioni orientate a un obiettivo come risposta all’esposizione in un ambiente esterno. Una funzionalità importante di questi sistemi è processare le variabili ambientali e connetterle all’oggetto a cui si riferiscono. Ad esempio, durante l’esecuzione di un sistema di riconoscimento facciale, l’algoritmo deve poter capire le caratteristiche del viso (oggetto in questione) per poterlo successivamente distinguere dallo sfondo dell’immagine e da altre parti del corpo (ambiente locale).
Gli algoritmi cognitivi usano la ricerca euristica per gestire le incertezze legate a questo problema, eliminando soluzioni lontane da quella ottimale. Oltre all'approccio basato sulla ricerca per risolvere i problemi delle scienze cognitive, esistono anche alcune tecniche che aiutano a migliorare l'accuratezza degli algoritmi di Computer Vision.
Nella prossima sezione studieremo gli algoritmi Minimax e Negamax e come questi migliorano l’efficienza della Computer Vision.
Algoritmi Minimax e Negamax in Python
Oltre agli algoritmi di ricerca discussi in precedenza, andiamo a esaminare alcuni algoritmi di ricerca con avversario, che si basano sempre su una tecnica di ricerca di base e che vengono impiegati per accelerare l'esecuzione degli algoritmi cognitivi.
Algoritmo Minimax
Gli algoritmi di ricerca combinatoria usano configurazioni di ricerca euristica per velocizzarne l'esecuzione. Questi algoritmi si usano principalmente nei giochi con più di un giocatore. Ad esempio nei giochi a due avversari ogni giocatore cerca di prevedere la mossa dell’avversario e cerca di agire in base a quello. Questo porta alla definizione di una funzione di minimizzazione, perché si vuole minimizzare il vantaggio futuro dell’avversario. Inoltre, per vincere la partita, il giocatore cerca anche di massimizzare la propria funzione obiettivo, da qui il nome MiniMax. L'euristica gioca un ruolo significativo in questa strategia. Ogni nodo dell'algoritmo ha una propria funzione euristica a esso associata e ciò aiuta il giocatore a scegliere la mossa successiva, spostandosi sul nodo che produrrebbe il maggior beneficio, cioè il maggior valore di euristica.
Alpha–Beta Pruning
Il Minimax è un algoritmo di ricerca combinatorio, ciò vuol dire che è un algoritmo di ricerca non informata che potenzialmente esplora tutto lo spazio di ricerca, comprese le parti irrilevanti. Questo porta a uno spreco di risorse computazionali e di memoria. Il pruning Alpha–Beta è una strategia di pruning che aiuta l’algoritmo a scegliere quali sono le parti importanti da visitare e quali invece tagliare, per avere risultati più veloci. Questo algoritmo lascia inesplorate le parti irrilevanti dello spazio di ricerca, risparmiando risorse preziose. L’obiettivo di questa tecnica è di evitare che l’algoritmo esplori porzioni dell’input che non potrebbero mai portare a una soluzione. In questo caso, Alpha è il massimo limite inferiore trovato finora nella ricerca, mentre Beta è il minimo limite superiore. La combinazione di questi due valori limita il movimento del giocatore.
Algoritmo Negamax
È molto simile all’algoritmo Minimax, anche se ha un’implementazione più sottile e raffinata. Infatti, nell’implementazione del minimax, si definiscono due euristiche distinte per il processo di massimizzazione (incremento delle possibilità di vittoria del giocatore) e minimizzazione (decremento delle possibilità di vittoria dell’avversario). Nel Negamax, invece, si usa la stessa funzione euristica per entrambi i task, riducendo il consumo generale di risorse computazionali.
Algoritmi Genetici di Ottimizzazione
Un’altra categoria di algoritmi di ricerca sono gli Algoritmi Genetici (GA), che lavorano sul concetto di selezione e di ordine naturale della gerarchia biologica. Sono un sottoinsieme del calcolo evolutivo, un ramo della computazione molto più ampio che si concentra sulla costruzione di algoritmi basati sui geni. John Holland, dell'Università del Michigan, e il suo collega David E. Goldberg sono considerati i pionieri del calcolo evolutivo e sono stati i responsabili della creazione di questa serie di metodi di ottimizzazione.
Gli algoritmi genetici prendono in input un pool di possibili soluzioni per un dato problema, e tutte queste possibilità subiscono una serie di mutamenti e ricombinazioni, in maniera simile a ciò che avviene in genetica. Si producono quindi dei figli e questo processo si ripete per più generazioni.
Ogni figlio è associato a un valore di fitness. Tale valore si basa sulla funzione obiettivo che l’algoritmo genetico prova a risolvere, in modo da dare precedenza alle generazioni con valori di fitness maggiori, dando loro la possibilità di incrociarsi per produrre individui sempre più forti. Questo processo prosegue finché non si raggiunge un criterio di arresto. In effetti, gli algoritmi genetici sono un’implementazione della teoria Darwiniana di sopravvivenza del più forte.
La struttura di un algoritmo genetico è altamente randomizzata e ciò fornisce buoni vantaggi per ottimizzare gli algoritmi di elaborazione delle immagini. Gli algoritmi genetici lavorano nella ricerca locale molto meglio rispetto a tutti gli altri algoritmi di ricerca data la loro caratteristica intrinseca di lavorare con dati storici, e poiché le immagini fanno parte di un ambiente complesso basato su vettori, questo tipo di ricerca ottimizzata consente una migliore elaborazione e quindi un'esecuzione più veloce delle tecniche di Computer Vision.
Di seguito, sono riportati i passaggi in cui operano gli algoritmi genetici. Questi passaggi sono generalmente sempre sequenziali e alcuni potrebbero essere ripetuti, in base alla precisione dell'algoritmo.
- Step 1: quando viene letto l’input, il primo passo è generare una possibile soluzione in maniera casuale, senza tener conto della sua accuratezza.
- Step 2: viene assegnato un valore di fitness alla soluzione iniziale, che viene mantenuto come metro di comparazione per tutte le future generazioni di soluzioni.
- Step 3: si applicano mutazioni e incroci sulla soluzione selezionata, che poi vengono ricombinate. Dalla combinazione delle soluzioni generate si estrae quella col maggior valore di fitness.
- Step 4: all’interno della popolazione vengono inseriti i figli della soluzione che ha generato la fitness migliore e le nuove soluzioni vengono poi incrociate e mutate e viene poi valutato il valore di fitness del risultato della mutazione.
- Step 5: se la nuova soluzione soddisfa la condizione di arresto, allora si arrestano le mutazioni e questa viene scelta come soluzione principale, altrimenti si ripete lo Step 4, attuando altre mutazioni e incroci, fino al raggiungimento di una soluzione che soddisfa la condizione.
# Per questo progetto useremo la libreria PyGrad, creata e resa open–source da Ahmed Gad.
# Qui si trovano menzioni e crediti al suo articolo e tutorial sugli algoritmi genetici
# https://www.linkedin.com/pulse/genetic–algorithm–implementation–python–ahmed–gad/
# Per lavorare con i GA ci servono anche altre librerie
pip install pygad
import numpy
import functools
import operator
import matplotlib.pyplot
# Importiamo imageio per leggere un file di immagine
# Maggiori informazioni del pacchetto pygad di PyPi sono disponibili su: https://pypi.org/project/pygad/
import imageio
import pygad
# Importiamo l’immagine che vogliamo riprodurre usando i GA
input_image = imageio.imread('test_flower.jpg')
input_image = numpy.asarray(input_image/255, dtype=numpy.float)
# Creiamo una rappresentazione monodimensionale dell’immagine
def image_to_vector(img_array):
return numpy.reshape(a=img_array, newshape=(functools.reduce(operator.mul, img_array.shape)))
# Convertiamo il vettore 1D in un array
def vector_to_array(input_vector, shape):
# Controlliamo se è possibile effettuare il reshape
if len(input_vector) != functools.reduce(operator.mul, shape):
raise ValueError("Reshaping failed")
return numpy.reshape(a=input_vector, newshape=shape)
# Immagine target dopo la codifica
image_encode = image_to_vector(input_image)
# Calcoliamo il valore di fitness per una soluzione random presa dalla popolazione
# Lo calcoliamo come la somma dei valori assoluti delle differenza tra i singoli valori dei geni
def fitness_func(int_one, int_two):
fitness_value = numpy.sum(numpy.abs(image_encode–int_one))
# Prendiamo il negative del valore di fitness per averli in ordine crescente
fitness_value = numpy.sum(image_encode) – fitness_value
return fitness_value
# Salviamo il risultato dell’esecuzione su una nuova immagine
# Enumeriamo anche il numero di iterazioni impiegate
def callback_func(genetic_var):
if genetic_var.generations_completed % 500 == 0:
matplotlib.pyplot.imsave('Final_GA_Image_'+str(genetic_var.generations_completed)+'.png', vector_to_array(genetic_var.best_solution()[0], input_image.shape))
# Inizializziamo la classe Genetic Algorithm con i seguenti parametri
genetic_var = pygad.GA(num_generations=20999,
num_parents_mating=12, # Numero di soluzioni parent da considerare
fitness_func=fitness_func, # Scelta della funzione di fitness
init_range_low=0, # Punto d’ingresso più basso (intero tra 0–1)
init_range_high=1, # Punto di uscita più alto (intero tra 0–1)
sol_per_pop=22, # Numero di popolazioni usate
num_genes=input_image.size, # Numero di geni usati
mutation_by_replacement=True,
mutation_percent_genes=0.02, # % dei geni della popolazione da mutare
mutation_type="random", # tipo di mutazione
callback_generation=callback_func,
random_mutation_min_val=0,
random_mutation_max_val=1) # valori minimi e massimi di mutazione (range 0–1)
# Eseguiamo l’istanza GA
genetic_var.run()
# Visualizziamo graficamente l’esecuzione di GA nel tempo per vedere come evolve l’immagine
genetic_var.plot_result()
# Vediamo alcune metriche per la scelta della soluzione ottima
int_one, result_fit, int_two = genetic_var.best_solution()
print("Selected Solution's Fitness Value = {result_fit}".format(result_fit=result_fit))
print("Iteration of the Selected Solution : {int_two}".format(int_two=int_two))
if genetic_var.best_solution_generation != –1:
print("Selected Solution was reached at the {best_solution_generation} generation.".format(best_solution_generation=genetic_var.best_solution_generation))
final_result = vector_to_array(int_one, input_image.shape)
matplotlib.pyplot.imshow(final_result)
matplotlib.pyplot.title("PyGAD & GARI for Reproducing Images")
matplotlib.pyplot.show()
>>>
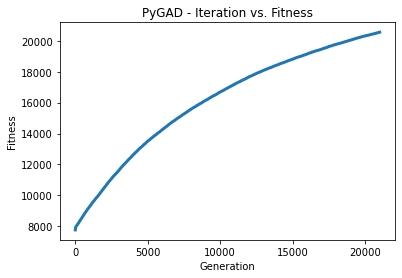 >>> Selected Solution's Fitness Value = 20551.29116769081
>>> Iteration of the Selected Solution : 0
>>> Selected Solution was reached at the 20998 generation.
>>>
>>> Selected Solution's Fitness Value = 20551.29116769081
>>> Iteration of the Selected Solution : 0
>>> Selected Solution was reached at the 20998 generation.
>>>
 # Ecco l’immagine generata al GA a seguito di 20998 mutazioni dell’input.
# Si possono ottenere soluzioni migliori se facciamo girare l’algoritmo per più iterazioni
# Ecco l’immagine generata al GA a seguito di 20998 mutazioni dell’input.
# Si possono ottenere soluzioni migliori se facciamo girare l’algoritmo per più iterazioni
Image Processing in Python
L’Image Processing non è altro che la conversione di un’immagine in forma digitale al fine di applicare operazioni su di essa, generalmente per applicare filtri o per estrarre feature dall’immagine. Può essere visto come una forma di distribuzione del segnale in cui l’input è generalmente sotto forma di immagini, come immagini statiche, video, film in movimento, ecc.
Le immagini vengono trattate come segnali bidimensionali e convertite in matrici. Lo scopo dell’Image Processing è visualizzare l’immagine in input, ripulirla da qualsiasi rumore, e cercare pattern e riconoscere le caratteristiche al suo interno. Nel dominio della Computer Vision, l’Image Processing viene anche chiamata Digital Image Processing.
L'elaborazione delle immagini è la fase preliminare di feature engineering di qualsiasi problema di Computer Vision. Sotto è mostrata una rappresentazione del funzionamento dell’image processing. Nell’immagine possiamo vedere alcuni termini chiave usati nelle pipeline di elaborazione delle immagini.
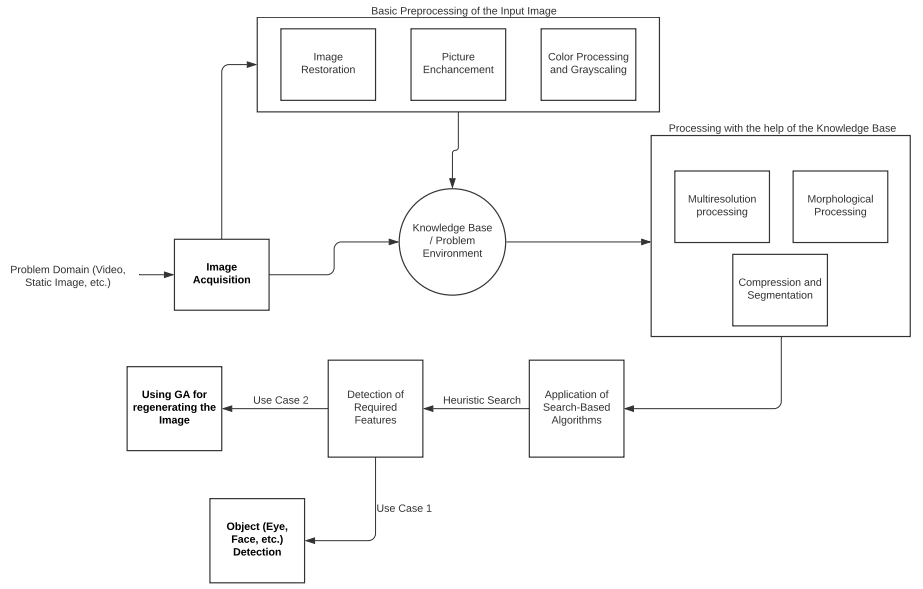
- Knowledge Base: tutti i problemi richiedono un proprio dominio di lavoro. Ad esempio, un video che mostra una partita di cricket richiederebbe un ambiente generale costituito dalle attrezzature, dal campo di gioco e dai giocatori. Allo stesso modo, anche i processi di elaborazione delle immagini richiedono una propria base di conoscenza, un database in cui sono codificate tutte le informazioni riguardo il dominio del problema. L’algoritmo di Image Processing effettua operazioni continue sulla knowledge base per verificare che il processo stia operando in maniera accurata.
- Elaborazione morfologica: è un processo basato sulla forma e dimensione dell’immagine. L’elaborazione morfologica si accorda con operazioni e funzioni che hanno lo scopo di estrarre componenti dell'immagine che rappresenterebbero bene l'immagine nelle sue dimensioni (forma, dimensione e inclinazione).
- Image Segmentation: nei sistemi di Computer Vision, la segmentazione è il processo di partizionamento dell’immagine in gruppi di pixel più piccoli o in oggetto. L’obiettivo finale dell’image segmentation è rappresentare l’immagine in maniera più significativa possibile per semplificare il processo di analisi. Viene inoltre assegnata un’etichetta a ogni pixel per facilitare il lavoro agli algoritmi di machine learning e di computer vision.
- Step nell’elaborazione di un’immagine: l'Image Processing è un processo che si compone di più fasi che non può essere definito come una successione di passaggi distinti, perché gli step sono dinamici e potrebbero essere ripetuti più di una volta. Vediamo una pipeline generale di elaborazione di immagini:
- il primo passo è l’acquisizione dell’immagine, che si occupa del modo in cui si reperisce l’immagine da dare in input all’algoritmo;
- dopo aver catturato l’immagine, si effettuano diverse operazioni di pre–processing, come il ridimensionamento e la pulitura dal rumore o la rimozione delle increspature;
- le increspature sono la base per classificare le immagini in più gradi di risoluzione. Suddividere le immagini in segmenti o regioni più piccole è un passaggio importante per comprimere l’immagine;
- una volta compressa l’immagine la si converte in una matrice, su cui vengono applicati gli algoritmi di ricerca discussi in precedenza;
- lo scopo finale di un algoritmo di image processing potrebbe essere quello di rilevare una parte dell’immagine o di generare la stessa immagine con diverse configurazioni.
Lettura delle immagini, conversione del colore e Rilevazione dei Bordi
Funzioni di OpenCV per l’Image Processing
OpenCV è la libreria più usata per l’elaborazione delle immagini e include funzionalità per lavorare coi video, coi volti, e molto altro. L’architettura sottostante OpenCV usa algoritmi di Machine Learning per svolgere i task di image processing. Dal momento che lavorare con le immagini è molto più complicato che lavorare coi numeri, OpenCV dispone di un’ampia collezione di algoritmi che si coordinano tra loro suddividendo il task di riconoscimento in porzioni molto piccole. In queste implementazioni ci sono vari algoritmi di ricerca che abbiamo visto in precedenza. Per iniziare con OpenCV, esamineremo le funzioni di base per la lettura, la scrittura e la visualizzazione di immagini in Python:
imread(): questa funzione permette all’utente di fornire immagini in input. Legge le immagini in diversi formati, tra cui PNG, JPEG, JPG e TIFF. Prende come argomenti il nume del file, il path e l’estensione.imshow(): questa funzione si usa per visualizzare un’immagine in Python su una finestra esterna. La finestra che genera il risultato si adatta automaticamente alla dimensione dell’immagine. Anche questa funzione supporta numerosi formati di immagine e prende in input il nome del file, il path e l’estensione.imwrite(): questa funzione si usa per scrivere dati binary su un file immagine. Il caso d'uso generale è convertire il tipo del file. La funzione write può salvare le immagini in formati come PNG, JPEG, JPG, TIFF, ecc. L'estensione desiderata viene passata come argomento, insieme al nome del file.
Lavorare con le immagini in ambiente Jupyter: Quando si esegue un'istanza Jupyter di Python per usare OpenCV, la funzione imshow() genera il suo output in una nuova finestra. Questa nuova casella immagine utilizza il kernel Python in esecuzione su Jupyter per elaborare il codice. Poiché entrambe le esecuzioni funzionano sullo stesso kernel in una shell interattiva, il kernel si blocca quando il programma viene eseguito. Per risolvere questo problema, dobbiamo chiudere programmaticamente le finestre aperte, ed è qui che diventa utile la funzione cv2.destroyAllWindows().
Passiamo ora al codice che ci aiuterà a capire come leggere i file immagine in Python, convertire le immagini in scala di grigi e rilevarne i bordi utilizzando OpenCV. Queste operazioni sono alla base della maggior parte degli algoritmi di Image Processing e Computer Vision.
# Possiamo installare questo pacchetto con l’aiuto del comando:
pip install opencv_python–X.X–cp36–cp36m–winX.whl
# Altrimenti possiamo usare il comando specifico per l’ambiente anaconda che può essere eseguito da console per installare OpenCV
conda install –c conda–forge opencv
import cv2
check_image = cv2.imread('test_flower.jpg')
cv2.imshow('Image of a Flower',check_image)
cv2.waitKey(0) # rimane in attesa di un’azione
# Nota: La funzione destroyallWindows() distrugge tutte le finestre create.
cv2.destroyAllWindows()
>>> <function destroyAllWindows>
>>>
 # Salviamo l’immagine in un formato diverso
# L’output True indica che la creazione della nuova immagine è avvenuta correttamente
cv2.imwrite('image_flower.png',check_image)
>>> True
# cvtColor() è una funzione per la conversione del colore che serve a modificare le tonalità di colore dell’immagine
image_new = cv2.cvtColor(check_image, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayscaled Flower',image_new)
cv2.waitKey(0)
cv2.destroyAllWindows()
>>>
# Salviamo l’immagine in un formato diverso
# L’output True indica che la creazione della nuova immagine è avvenuta correttamente
cv2.imwrite('image_flower.png',check_image)
>>> True
# cvtColor() è una funzione per la conversione del colore che serve a modificare le tonalità di colore dell’immagine
image_new = cv2.cvtColor(check_image, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayscaled Flower',image_new)
cv2.waitKey(0)
cv2.destroyAllWindows()
>>>
.png.aspx;) # Edge Detection
# Usiamo la funzione Canny () per riconoscere i bordi dell’immagine.
cv2.imwrite('Edge_Flowers.jpg', cv2.Canny(check_image, 200, 300))
# Mostriamo l’immagine dei bordi
cv2.imshow('Edges of the Image', cv2.imread('Edge_Flowers.jpg'))
cv2.waitKey(0)
cv2.destroyAllWindows()
>>>
# Edge Detection
# Usiamo la funzione Canny () per riconoscere i bordi dell’immagine.
cv2.imwrite('Edge_Flowers.jpg', cv2.Canny(check_image, 200, 300))
# Mostriamo l’immagine dei bordi
cv2.imshow('Edges of the Image', cv2.imread('Edge_Flowers.jpg'))
cv2.waitKey(0)
cv2.destroyAllWindows()
>>>
 # Abbiamo completato l’edge detection e la conversione in scala di grigi della nostra immagine
# Abbiamo completato l’edge detection e la conversione in scala di grigi della nostra immagine
La classificazione delle immagini in scala di grigi e il rilevamento dei bordi sono la prima parte di ogni algoritmo di elaborazione. Il motivo è che le immagini in scala di grigi possono essere rappresentate come una matrice di valori binari (0 – nero, 1 – bianco), ciò semplifica il lavoro dell’algoritmo. Allo stesso modo, le immagini con bordi hanno una superficie inferiore, e quindi riducono la dimensione complessiva del dominio del problema, questo accelera il processo di analisi.
Face e Eye Detection
Per lavorare con cose come volti e occhi, l'algoritmo suddivide il processo di rilevamento in molte attività (6000 o più) più piccole che rilevano segmenti molto piccoli (raccolta di pixel) dell'immagine e verificano se tali segmenti corrispondono a parti di viso. OpenCV utilizza le cascade per risolvere questa parte del problema. Una cascade è definita come una raccolta di cascade. Le cascade sono una batteria predefinita di test a cui l’algoritmo deve sottoporsi per passare all'iterazione successiva. Le cascade in OpenCV sono file XML che contengono i dati utilizzati dagli algoritmi per l’object detection. Le cascade esistono sia per oggetti umani che per quelli inanimati.
Face Detection
Il riconoscimento facciale è il ramo dell’object detection che tratta l’identificazione di volti in un’immagine. Useremo il file [“haarcascades/haarcascade_frontalcatface.xml”] come cascade per la Face Detection. Il riconoscimento facciale si compone dei seguenti passaggi:
- l’immagine viene fornita come input al programma;
- si importano le cascade e si inizializza la classe face cascade con l'immagine di input;
- si effettua la conversione in scala di grigi, dopodiché si usa la funzione
detectMultiScale() per identificare le porzioni di immagine che contengono un volto. Questa funzione prende in input un’immagine in scala di grigi, un fattore di scala (alcune immagini potrebbero essere più vicine alla fotocamera e sembrare più grandi, quindi l'immagine dovrebbe essere ridimensionata per rappresentare tutti gli oggetti possibili in un intervallo di scala specificato), il valore minimo dei vicini che definiscono l'oggetto rilevato vicino al viso e l'argomento della dimensione minima che fornisce la dimensione di ciascuna finestra di attività individuale;
- infine, l’algoritmo traccia un rettangolo sui volti individuati.
import cv2
import numpy as np
# Definiamo i path necessari
image_path = './Elon.jpg'
haarcasc_path = 'D:/Users/Anaconda/pkgs/libopencv–4.0.1–hbb9e17c_0/Library/etc/haarcascades/haarcascade_frontalcatface.xml'
# Creiamo la haar cascade
face_cascade_class = cv2.CascadeClassifier(haarcasc_path)
# Leggiamo l’immagine
test_image = cv2.imread(image_path)
gray_image = cv2.cvtColor(test_image, cv2.COLOR_BGR2GRAY)
# Riconosciamo i volti nelle immagini
checked_faces = face_cascade_class.detectMultiScale(
gray_image,
scaleFactor=1.2,
minNeighbors=3,
minSize=(10, 10)
)
# Tracciamo un rettangolo intorno ai volti
for (x, y, w, h) in checked_faces:
cv2.rectangle(test_image, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imshow("Faces found", test_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('Face_EM_final.jpg',test_image)
>>> True
>>>
.png.aspx;) # Il risultato mostra il bordo del viso di Elon
# Il risultato mostra il bordo del viso di Elon
Questo modello sembra non aver identificato con precisione il volto. Si può però migliorare regolando il fattore di scala e cambiando la risoluzione dell'immagine. Pertanto, è sempre considerata buona pratica testare l'analisi con una combinazione di più set di configurazioni per vedere quale funziona perfettamente.
Eye Detection
Il riconoscimento degli occhi è il processo successivo al riconoscimento facciale. L'algoritmo di Eye Detection non può funzionare senza prima separare il volto dall'ambiente circostante. Si utilizza il file cascade ["haarcascades / haarcascade_eye.xml"] per riconoscere gli occhi. Tutti gli altri passaggi sono simili a quelli eseguiti nella Face Detection.
import cv2
import cv2
# Importiamo i path necessari
image_path = './Eyes.jpg'
eye_haar_cascade = 'D:/Users/Anaconda/pkgs/libopencv–4.0.1–hbb9e17c_0/Library/etc/haarcascades/haarcascade_eye.xml'
eye_cascade_class = cv2.CascadeClassifier(eye_haar_cascade)
test_image = cv2.imread(image_path)
gray_image = cv2.cvtColor(test_image, cv2.COLOR_BGR2GRAY)
eyes = eye_cascade_class.detectMultiScale(gray_image, 1.2, 5)
for (ex,ey,ew,eh) in eyes:
test_image_eyes = cv2.rectangle(test_image,(ex,ey),(ex+ew, ey+eh),(0,255,0),2)
cv2.imshow("Eyes found", test_image_eyes)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('Eye_AB.jpg',test_image_eyes)
>>> True
>>>
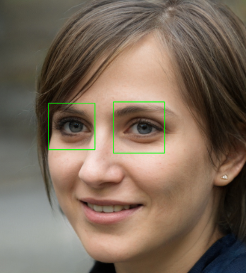 # Osserviamo che l’algoritmo è in grado di distinguere gli occhi dall’immagine di input
# Osserviamo che l’algoritmo è in grado di distinguere gli occhi dall’immagine di input
Come nella Face Detection, anche gli algoritmi di Eye Detection possono essere raffinati per migliorarne il funzionamento, modificando i parametri in ingresso alla funzione di riconoscimento.
Prossimamente
Al termine dell’introduzione alla Computer Vision, abbiamo concluso la nostra avventura nelle Scienze Cognitive applicate all'intelligenza artificiale. Gli algoritmi cognitivi più importanti su cui abbiamo lavorato finora sono l'NLP (Natural Language Processing), il riconoscimento vocale e, ora, l'elaborazione delle immagini. Nei prossimi capitoli approfondiremo un caso di studio che coinvolge le scienze cognitive.
- Caso di Studio di Scienza Cognitiva
- Capire dati facciali
- Modellazione cognitiva