Richiami di Machine Learning
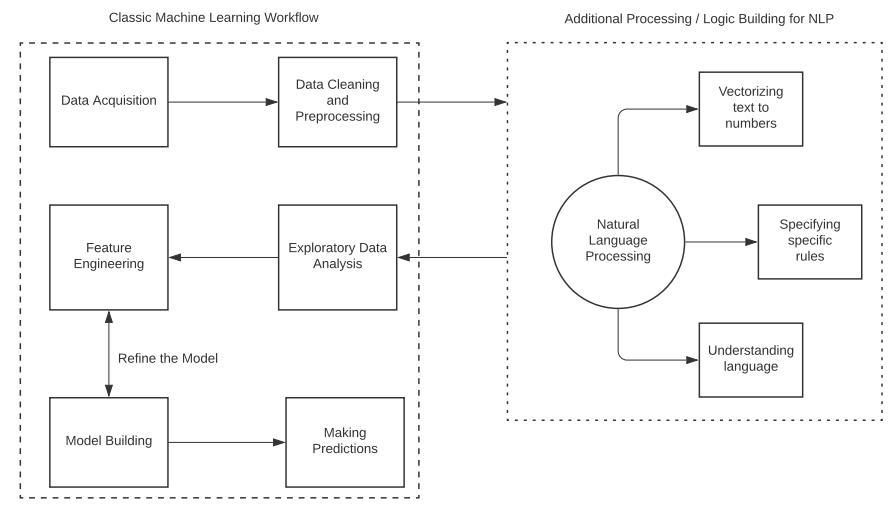
Nel primo caso di studio, avevamo costruito una pipeline di machine learning per risolvere un problema di predizione. Avevamo previsto i prezzi di alcuni immobili della regione di Ames, in Iowa, sulla base di fattori tra i quali il prezzo, la qualità dell’edificio e del vicinato, come anche di altri elementi. Ricordiamo quali sono state le operazioni implementate nella pipeline, cioè quelle che tra l’altro costituiscono la base di tutti i problemi di machine learning (ML):
- Acquisizione dei dati: ogni analisi richiede uno step di acquisizione e collezione dei dati. I dati possono essere prelevati da diverse fonti, come web crawl, data warehouse, stream di dati live come audio e video, e molto altro. I dati acquisiti possono essere memorizzati nell’ambiente di lavoro sotto forma di Dataframe, che permettono di lavorare agilmente con i costrutti di analisi in Python.
- Cleaning e Pre–processing: nella maggior parte dei casi, i dati grezzi contengono informazioni che non aiutano l’analisi, ma che anzi possono compromettere i risultati. Per questo, una volta completata la fase di acquisizione, bisogna eseguire una fase di ripulitura e pre–processing dei dati che include la rimozione di outlier, la divisione degli attributi dalle etichette, la standardizzazione degli attributi, la rimozione di colonne poco significative, il mapping delle variabili categoriche, eccetera.
- Analisi Esplorativa del Dato (EDA): l’operazione di EDA è molto importante nei passaggi iniziali dell’analisi, in quanto svela informazioni generali sui dati. L’EDA aiuta a comprendere meglio i dati, a ricercare schemi e a ottenere diverse misure statistiche come la media, la mediana, la deviazione standard e la varianza.
- Costruzione e addestramento dei modelli: una volta finito di preparare i dati per l’analisi e dopo averli standardizzati, siamo pronti per costruire il modello di machine learning. L’idea dietro la costruzione di un modello è di fornirgli una quantità abbondante di dati da cui apprendere. L’algoritmo di apprendimento usa questi dati per apprendere gli schemi che incorrono tra i dati e si addestra per funzionare anche su dati sconosciuti dello stesso tipo. Esiste una molteplicità di algoritmi di machine learning da cui poter scegliere sulla base del problema che si vuole risolvere e del tipo di soluzione desiderata, così come abbiamo visto nel primo caso di studio.
- Predire i risultati: infine, il risultato del nostro lavoro sono le predizioni che il modello fa sui dati sconosciuti. Una volta che il modello è stato addestrato sui dati di training, riesce a capire come i vari punti all'interno del contesto sono correlati tra loro. Durante la fase di predizione, l'algoritmo viene alimentato con una variabile di input. Il modello acquisisce questo input e prevede il valore di output desiderato.
In questo nuovo caso di studio, andremo a costruire una pipeline di machine learning simile per l’analisi di dati basati sul linguaggio. L’unica aggiunta che facciamo al nostro modello è di convertire il testo in numeri e applicare tecniche di processing adatte per preservare l’importanza che le singole parole hanno nel testo in input. Iniziamo a fare pratica con il Natural Language Processing (NLP) integrandolo nel nostro workflow di Machine Learning.
Aggiungere un livello di NLP nel Machine Learning Workflow
Per includere il Natural Language Processing nella pipeline di machine learning, dobbiamo aggiungere solo alcuni passaggi nella fase di processing e pulitura dei dati. Gli algoritmi di training e verifica invece continueranno a funzionare come prima. L’unica modifica logica al workflow sta nel convertire il testo in dati numerici che gli algoritmi di ML riescono a processare. Durante questa conversione, ci sono numerosi fattori da considerare. Ad esempio, il numero di volte in cui una parola occorre in un testo potrebbe essere utile nel determinare l’argomento di cui si parla.
Approcci ibridi di NLP e ML
Il linguaggio naturale è spesso fuorviante, dal momento che i toni, le interpretazioni e i significati possono variare da persona a persona, e questi aspetti sono difficili da integrare all’interno di un modello. Infatti, il machine learning da solo non può fungere da soluzione per il NLP. I modelli di machine learning sono utili per riconoscere il sentimento generale di un documento oppure per comprendere quali entità sono presenti in un testo, ma si scontrano per estrarre temi o abbinare sentimenti a singole entità o temi. Pertanto, in un approccio ibrido di NLP, possiamo spiegare le regole necessarie al modello di ML. Tali regole sono generalmente convenzioni della lingua e aiutano l'algoritmo a rendere più stretta la relazione tra la classificazione e l'intuizione umana.
Il modello Bag of Words (BOW) in NLTK
Il Bag of Words (BoW) è un modello di NLP usato per estrarre feature dai testi e per prepararli all’uso dei modelli di machine learning. BoW svolge un ruolo importante durante l’estrazione delle feature dai dati in input. Una volta estratte, infatti, queste feature vengono etichettate con dati numerici con cui gli algoritmi di ML possono lavorare efficientemente. L’approccio Bag of Words è il più semplice in quanto non assegna dei pesi alle parole, ma consiste nel separare tutte le parole in singoli token, ai quali viene assegnato un valore numerico casuale senza ordine di precedenza. Possiamo implementare il modello BoW con la funzione CountVectorizer della libreria sklearn di Python. Vediamo una piccola applicazione di questo modello.
# Usiamo il CountVectorizer di Scikit learn per convertire il testo in vettori numerici
from sklearn.feature_extraction.text import CountVectorizer
input_sent = ['Demonstration of the BoW NLTK model', 'This model builds numerical features for text input']
input_cv = CountVectorizer()
features_text = input_cv.fit_transform(input_sent).todense()
print(input_cv.vocabulary_)
>>> {'demonstration': 2, 'of': 9, 'the': 11, 'bow': 0, 'nltk': 7, 'model': 6, 'this': 12, 'builds': 1, 'numerical': 8, 'features': 3, 'for': 4, 'text': 10, 'input': 5}
# Questo ci permette di costruire dei vettori di feature che potranno essere usati con successo negli algoritmi di ml
Matrice Document–Term
Siccome BoW non assegna dei pesi alle singole parole, può capitare di trovarci di fronte scenari in cui questo fornisce risultati errati. La matrice Document–Term è un costrutto che contiene il numero delle occorrenze per ogni parola di un documento. Seguendo questa logica, tutte le parole rappresentate da un BoW possono essere viste come una sequenza pesata di parole. Esiste un altro algoritmo, il TF–IDF, che si basa su BoW e usa i pesi delle parole per costruire i vettori.
TF–IDF (Term Frequency – Inverse Document Frequency)
Nel modello Bag of Words le parole hanno peso uniforme. Tuttavia, in uno scenario reale, gli argomenti di discussione si possono inferire solo conoscendo quante volte le parole sono ripetute all’interno del contesto. La logica del TF–IDF è che le parole che contribuiscono maggiormente alla determinazione dei risultati sono quelle che hanno bassa frequenza nell’insieme di tutti i documenti ma alta frequenza in un singolo documento. Come suggerisce anche il nome, il TF–IDF è una combinazione di due elementi, la term frequency e la document frequency. In sostanza, afferma che il valore di una parola nella classificazione aumenta tanto maggiori sono la sua term frequency, ovvero il numero di occorrenze in un documento, e l’inversa della sua document frequency, cioè il numero dei documenti in cui la parola è presente. Un utilizzo tipico del TF–IDF lo troviamo negli algoritmi di Search Engine Optimization.
- TF = (Occorrenza della parola in un documento) / (Numero totale di parole nel documento)
- IDF = Log ((Numero totale di documenti) / (Numero di documenti che contengono la parola))
TF–IDF con la libreria Scikit–Learn
La classe TfidfVectorizer della libreria Scikit–Learn di Python fornisce uno strumento immediato per implementare l’algoritmo TF–IDF su dati testuali. Questa classe può essere usata per convertire feature di testo in vettori delle feature TF–IDF. Proviamo a comprendere il funzionamento dell’algoritmo con una pseudo implementazione.
# Pseudo implementazione del TF–IDF
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
input_vector = TfidfVectorizer (max_features=3000, min_df=6, max_df=0.75, stop_words=stopwords.words('english'))
output_features = input_vector.fit_transform(input_sent).toarray()
Vediamo i parametri passati alla funzione TfidfVectorizer:
- Il parametro
max_features è stato settato a 3000, significa che l’algoritmo userà solo le prime 3000 parole più frequenti, sotto l’assunzione che le parole meno frequenti generalmente non sono utili alla classificazione.
- Il parametro
max_df denota la porzione di documenti che contengono la parola. In questo caso l’algoritmo cercherà solo le parole presenti nel 75% dei documenti. Il motivo è che le parole presenti in tutti i documenti spesso non sono affatto utili.
- Il parametro
min_df serve a definire la soglia minima del numero di documenti che dovrebbero contenere le parole. In questo caso, l’algoritmo andrà a considerare solo le parole presenti in almeno 6 documenti.
Nella prossima sezione, inizieremo a lavorare su uno scenario in cui si richiede il Natural Language Processing. In particolare, vedremo come cogliere le emozioni umane attraverso delle espressioni scritte da alcune persone.
Caso di Studio 2: Sentiment Analysis
Definizione del problema
Il dataset di input contiene dei tweet pubblicati da degli utenti riguardo sei linee aeree degli Stati Uniti. L’obiettivo è di categorizzare i tweet in sentiment positivo, neutro o negativo. Potremo fare la categorizzazione usando un convenzionale algoritmo di learning supervisionato, in cui i dati di training saranno tweet già etichettati. Con un training set di questo tipo dovremmo poter costruire un modello in grado di categorizzare i sentimenti dei tweet.
Soluzione
L’approccio risolutivo vedrà l’implementazione di una pipeline di machine learning simile a quella usata nel Caso di Studio 1. Per iniziare, importeremo le librerie necessarie alla nostra analisi, quindi effettueremo l’analisi esplorativa dei dati, in cui andremo a esplorare la correlazione tra diverse sezioni dei dati e a capire meglio in generale l’input.
In seguito, introdurremo un nuovo step di pre–processing in cui attueremo l’elaborazione del testo. Siccome gli algoritmi di machine learning lavorano più efficientemente su dati numerici, trasformeremo l’input testuale in input numerico, come abbiamo visto per il modello Bag of Word (BoW). In ultimo, una volta terminata la fase di pre–processing costruiremo un modello di ML e lo eseguiremo sull’intero dataset per conoscerne l’accuratezza.
# Importiamo le librerie necessarie
import numpy as np
import pandas as pd
import re
import nltk
import matplotlib.pyplot as plt
%matplotlib inline
# Data Source: https://raw.githubusercontent.com/kolaveridi/kaggle–Twitter–US–Airline–Sentiment–/master/Tweets.csv
import_data_url = "https://raw.githubusercontent.com/kolaveridi/kaggle–Twitter–US–Airline–Sentiment–/master/Tweets.csv"
sentiment_tweets = pd.read_csv(import_data_url)
# Eseguiamo EDA sul dataset per comprenderlo meglio.
# Vediamo la distribuzione dei tweet in base alla linea aerea
sentiment_tweets.airline.value_counts().plot(kind='pie', label='')
>>> <AxesSubplot:>
.png.aspx;) # Vediamo la porzione dei sentimenti mostrata dagli utenti
sentiment_tweets.airline_sentiment.value_counts().plot(kind='pie', autopct='%1.0f%%', colors=["brown", "orange", "blue"])
>>> <AxesSubplot:ylabel='airline_sentiment'>
# Vediamo la porzione dei sentimenti mostrata dagli utenti
sentiment_tweets.airline_sentiment.value_counts().plot(kind='pie', autopct='%1.0f%%', colors=["brown", "orange", "blue"])
>>> <AxesSubplot:ylabel='airline_sentiment'>
.png.aspx;) airline_grouped_sentiment = sentiment_tweets.groupby(['airline', 'airline_sentiment']).airline_sentiment.count().unstack()
airline_grouped_sentiment.plot(figsize=(8,5), kind='bar', title='Individual Sentiments for Airlines', xlabel='Airline Company', ylabel='Sentiment Count')
>>> <AxesSubplot:title={'center':'Individual Sentiments for Airlines'}, xlabel='Airline Company', ylabel='Sentiment Count'>
airline_grouped_sentiment = sentiment_tweets.groupby(['airline', 'airline_sentiment']).airline_sentiment.count().unstack()
airline_grouped_sentiment.plot(figsize=(8,5), kind='bar', title='Individual Sentiments for Airlines', xlabel='Airline Company', ylabel='Sentiment Count')
>>> <AxesSubplot:title={'center':'Individual Sentiments for Airlines'}, xlabel='Airline Company', ylabel='Sentiment Count'>
.png.aspx;) import seaborn as sns
sns.barplot(x='airline_sentiment', y='airline_sentiment_confidence' , data=sentiment_tweets)
>>> <AxesSubplot:xlabel='airline_sentiment', ylabel='airline_sentiment_confidence'>
import seaborn as sns
sns.barplot(x='airline_sentiment', y='airline_sentiment_confidence' , data=sentiment_tweets)
>>> <AxesSubplot:xlabel='airline_sentiment', ylabel='airline_sentiment_confidence'>
.png.aspx;) # Cleaning dei dati: i tweet possono contenere punteggiature e altri caratteri non rilevanti, per cui li rimuoviamo
# Dividiamo anche l’insieme delle feature dalle etichette
feature_set = sentiment_tweets.iloc[:, 10].values
label_set = sentiment_tweets.iloc[:, 1].values
cleaned_feature_set = list()
for input_phrase in range(0, len(feature_set)):
# 1. Rimozione dei caratteri speciali (*,etc.) e single–word (a,an,etc.)
clean_feature = re.sub(r'\W', ' ', str(feature_set[input_phrase]))
clean_feature= re.sub(r'\s+[a–zA–Z]\s+', ' ', clean_feature)
clean_feature = re.sub(r'\^[a–zA–Z]\s+', ' ', clean_feature)
# 2. Conversione in formato minuscolo
clean_feature = clean_feature.lower()
cleaned_feature_set.append(clean_feature)
# Convertiamo il testo in forma numerica: tutti i modelli statistici e di machine learning usano la matematica e i numeri per processare i dati
# Quindi, dato che il nostro input è testuale, useremo il TF–IDF per processarlo.
# Importiamo le librerie necessarie
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
input_vector = TfidfVectorizer (max_features=3000, min_df=6, max_df=0.8, stop_words=stopwords.words('english'))
cleaned_feature_set = input_vector.fit_transform(cleaned_feature_set).toarray()
# Ora usiamo la funzione train_test_split per dividere i dati in training e test set.
# Useremo il training set per addestrare il modello e trovare il modello che si adatta meglio al tipo di predizione
# Eseguiremo quest’ultimo sul test set per ottenere lo score finale di predizione
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(cleaned_feature_set, label_set, test_size=0.33, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Random Forest
rf_classifier = RandomForestClassifier(n_estimators=200, random_state=42)
rf_classifier.fit(X_train, y_train)
rf_classifier_score = rf_classifier.score(X_train, y_train)
# Linear Support Vector Machine
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
svc_classifier_score = svc_classifier.score(X_train, y_train)
# Regressione Logistica
lr_classifier = LogisticRegression(random_state=0, solver='lbfgs', multi_class='ovr').fit(X_train, y_train)
lr_classifier_score = lr_classifier.score(X_train, y_train)
# K–Nearest Neighbors
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train, y_train)
knn_classifier_score = knn_classifier.score(X_train, y_train)
# Confronto dei singoli score
accuracy_scores = []
Used_ML_Models = ['Random Forest Classification','Support Vector Machine Classification','Logistic Regression',
'KNN Classification']
accuracy_scores.append(rf_classifier_score)
accuracy_scores.append(svc_classifier_score)
accuracy_scores.append(lr_classifier_score)
accuracy_scores.append(knn_classifier_score)
score_comparisons = pd.DataFrame(Used_ML_Models, columns = ['Classifiers'])
score_comparisons['Accuracy on Training Data'] = accuracy_scores
score_comparisons
>>>
Classifiers Accuracy on Training Data
0 Random Forest Classification 0.992965
1 Support Vector Machine Classification 0.859808
2 Logistic Regression 0.820759
3 KNN Classification 0.797308
# Possiamo vedere che il classificatore Random Forest è quello che performa meglio
# Effettuiamo le predizioni finali usando l’algoritmo migliore
final_pred = rf_classifier.predict(X_test)
# Accuracy score finale
print(accuracy_score(y_test, final_pred))
>>> 0.7667632450331126
# Cleaning dei dati: i tweet possono contenere punteggiature e altri caratteri non rilevanti, per cui li rimuoviamo
# Dividiamo anche l’insieme delle feature dalle etichette
feature_set = sentiment_tweets.iloc[:, 10].values
label_set = sentiment_tweets.iloc[:, 1].values
cleaned_feature_set = list()
for input_phrase in range(0, len(feature_set)):
# 1. Rimozione dei caratteri speciali (*,etc.) e single–word (a,an,etc.)
clean_feature = re.sub(r'\W', ' ', str(feature_set[input_phrase]))
clean_feature= re.sub(r'\s+[a–zA–Z]\s+', ' ', clean_feature)
clean_feature = re.sub(r'\^[a–zA–Z]\s+', ' ', clean_feature)
# 2. Conversione in formato minuscolo
clean_feature = clean_feature.lower()
cleaned_feature_set.append(clean_feature)
# Convertiamo il testo in forma numerica: tutti i modelli statistici e di machine learning usano la matematica e i numeri per processare i dati
# Quindi, dato che il nostro input è testuale, useremo il TF–IDF per processarlo.
# Importiamo le librerie necessarie
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
input_vector = TfidfVectorizer (max_features=3000, min_df=6, max_df=0.8, stop_words=stopwords.words('english'))
cleaned_feature_set = input_vector.fit_transform(cleaned_feature_set).toarray()
# Ora usiamo la funzione train_test_split per dividere i dati in training e test set.
# Useremo il training set per addestrare il modello e trovare il modello che si adatta meglio al tipo di predizione
# Eseguiremo quest’ultimo sul test set per ottenere lo score finale di predizione
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(cleaned_feature_set, label_set, test_size=0.33, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Random Forest
rf_classifier = RandomForestClassifier(n_estimators=200, random_state=42)
rf_classifier.fit(X_train, y_train)
rf_classifier_score = rf_classifier.score(X_train, y_train)
# Linear Support Vector Machine
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
svc_classifier_score = svc_classifier.score(X_train, y_train)
# Regressione Logistica
lr_classifier = LogisticRegression(random_state=0, solver='lbfgs', multi_class='ovr').fit(X_train, y_train)
lr_classifier_score = lr_classifier.score(X_train, y_train)
# K–Nearest Neighbors
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train, y_train)
knn_classifier_score = knn_classifier.score(X_train, y_train)
# Confronto dei singoli score
accuracy_scores = []
Used_ML_Models = ['Random Forest Classification','Support Vector Machine Classification','Logistic Regression',
'KNN Classification']
accuracy_scores.append(rf_classifier_score)
accuracy_scores.append(svc_classifier_score)
accuracy_scores.append(lr_classifier_score)
accuracy_scores.append(knn_classifier_score)
score_comparisons = pd.DataFrame(Used_ML_Models, columns = ['Classifiers'])
score_comparisons['Accuracy on Training Data'] = accuracy_scores
score_comparisons
>>>
Classifiers Accuracy on Training Data
0 Random Forest Classification 0.992965
1 Support Vector Machine Classification 0.859808
2 Logistic Regression 0.820759
3 KNN Classification 0.797308
# Possiamo vedere che il classificatore Random Forest è quello che performa meglio
# Effettuiamo le predizioni finali usando l’algoritmo migliore
final_pred = rf_classifier.predict(X_test)
# Accuracy score finale
print(accuracy_score(y_test, final_pred))
>>> 0.7667632450331126
Osserviamo che lo score di predizione sul test set non è buono quanto quello sul training set. Tuttavia, dato che il Random Forest era la nostra soluzione migliore, per aumentare questo score potremmo costruire il modello con regole migliori. La fase di pre–processing è quella che fornisce regole aggiuntive per guidare l’algoritmo e aggiungere significato all’analisi. Costruire regole migliori può sempre migliorare l’accuratezza, poiché comunque la grammatica, le parti del discorso e le altre etimologie che usiamo nel linguaggio quotidiano non sono note ai modelli di NLP. Possiamo tuttavia dotare i modelli di queste regole durante la fase di creazione. Con questo concludiamo il nostro progetto di Sentiment Analysis e spostiamoci verso casi d’uso generali di Natural Language Processing.
Natural Language Processing e Casi d’Uso
L’NLP è un concetto di intelligenza artificiale per il riconoscimento e la comprensione dei linguaggi umani, sia in forma scritta che parlata. I casi d’uso dell’NLP sono molti e sono diffusi in molte aziende e ambiti di business. Discutiamo alcuni casi d’uso emblematici potenziati dall’NLP.
- Indagini Epidemiologiche: l’elaborazione dei linguaggi naturali può essere usata per leggere registri medici, diagnosi e altro materiale per predire anomalie nei sintomi. Ad esempio, Alibaba ha usato il modello di NLP StructBert per comprendere le variazioni dei disturbi influenzali durante la lotta al COVID–19 in Cina.
- Autenticazioni sicure: attraverso lo studio delle informazioni degli utenti si può usare l’NLP per generare domande avanzate per autenticare in sicurezza gli utenti di un sistema. Si usano modelli di Entity Recognition per estrarre risposte rilevanti da un questionario sulla sicurezza dell’utente. Per generare domande più avanzate si usano particolari reti neurali.
- Affermazione del Brand e ricerche di mercato: la Sentiment Analysis è ampiamente usata nelle analisi di mercato. Quando un utente acquista un prodotto gli viene chiesto di recensirlo e l’analisi delle recensioni aiuta a capire le caratteristiche del prodotto e a migliorarne i punti deboli. Aiuta anche a capire quali sono i brand e i prodotti preferiti dagli utenti.
- Chatbot: i chatbot vengono frequentemente usati in diversi siti web per aiutare a rispondere alle domande degli utenti. I chatbot si costruiscono con tecniche di NLP e usano modelli conversazionali per rispondere alle domande degli utenti con risposte rilevanti.
- Sfruttare l’intelligenza in tempo reale sui Mercati Finanziari: il mercato azionario è altamente sensibile alle notizie del mondo e ai cambiamenti nelle organizzazioni, e capire questi cambiamenti è fondamentale per prendere decisioni sul mercato. Per questo molte aziende usano l’NLP per elaborare le nuove notizie e gli aggiornamenti sui CDA delle aziende quotate per predire l’andamento futuro dei prezzi delle loro azioni.
- Organizzazioni della Difesa: gli organismi di difesa di numerosi stati, tra cui gli Stati Uniti, collaborano con aziende come Facebook, Google e Microsoft per mantenere un gran numero di informazioni reperibili pubblicamente in modo da costruire un modello di deep learning che legga le tendenze delle conversazioni e preveda eventuali violazioni di sicurezza nell’immediato futuro.
La categorizzazione del testo è una caratteristica importante usata dalla maggior parte degli algoritmi e l’NLP può essere usato anche a tal proposito. Vediamo un’implementazione in cui proviamo a categorizzare gli argomenti principali di alcune frasi di input.
# Importiamo le librerie necessarie
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
# Creiamo un dizionario per classificare i risultati
dict_cat = {'talk.religion.misc': 'Religious Content', 'rec.autos': 'Automobile and Transport','rec.sport.hockey':'Sport: Hockey','sci.electronics':'Content: Electronics', 'sci.space': 'Content: Space'}
data_train = fetch_20newsgroups(subset='train', categories = dict_cat.keys(), shuffle=True, random_state=3)
cv_vector = CountVectorizer()
data_train_fit = cv_vector.fit_transform(data_train.data)
print("\nTraining Data Dimensions:", data_train_fit.shape)
>>> Training Data Dimensions: (2755, 39297)
# Importiamo il trasformatore TF–IDF
tfidf_transformer = TfidfTransformer()
train_tfidf_transformer = tfidf_transformer.fit_transform(data_train_fit)
# Definiamo delle frasi di input per eseguire un esempio
sample_input_data = [
'The Apollo Series were a bunch of space shuttles',
'Islamism, Hinduism, Christianity, Sikhism are all major religions of the world',
'It is a necessity to drive safely',
'Gloves are made of rubber',
'Gadgets like TV, Refrigerator and Grinders, all use electricity'
]
# Usiamo il classificatore multinominale Baive Bayes col TF–IDF
input_classifier = MultinomialNB().fit(train_tfidf_transformer, data_train.target)
input_cv = cv_vector.transform(sample_input_data)
tfidf_input = tfidf_transformer.transform(input_cv)
predictions_sample = input_classifier.predict(tfidf_input)
for inp, cat in zip(sample_input_data, predictions_sample):
print('\nInput Data:', inp, '\n Category:', \
dict_cat[data_train.target_names[cat]])
>>>
Input Data: The Apollo Series were a bunch of space shuttles
Category: Content: Space
Input Data: Islamism, Hinduism, Christianity, Sikhism are all major religions of the world
Category: Religious Content
Input Data: It is a necessity to drive safely
Category: Automobile and Transport
Input Data: Gloves are made of rubber
Category: Automobile and Transport
Input Data: Gadgets like TV, Refrigerator and Grinders, all use electricity
Category: Content: Electronics
Abbiamo mostrato i risultati della categorizzazione delle frasi di input e con questo concludiamo la nostra analisi dei linguaggi naturali.
Prossimamente
Nei prossimi capitoli di questa serie lavoreremo su problemi che ruotano intorno al mondo del Natural Language Processing. Finora abbiamo appreso come l’NLP stia acquistando notevole popolarità tra gli algoritmi di Intelligenza Artificiale e abbiamo visto i passaggi da seguire per costruire una pipeline di elaborazione del linguaggio.
Sono molti i problemi che possono essere risolti con l’aiuto del NLP. Nei prossimi capitoli approfondiremo l'intelligenza artificiale cognitiva e vedremo i concetti di Computer Vision e analisi dei dati basata sul discorso parlato. Tutti i prossimi capitoli e modelli seguiranno una struttura e un flusso di lavoro simili a quelli che abbiamo discusso negli ultimi due casi di studio.
Alcuni concetti che vedremo sono:
- Lavorare con dati Speech–based;
- Pronuncia delle parole e segnali audio;
- Computer Vision in Python.