Architettura di un Progetto di Machine Learning
In questo capitolo ci concentreremo sulla parte del Machine Learning relativa al Data Analysis. Il processo di analisi inizia con l’acquisizione e la pulitura del dato. I dati possono essere prelevati da svariate fonti come siti web, video in streaming, dati finanziari e molto altro. La prima forma del dato è spesso una rappresentazione grezza e necessita di pulitura e altre elaborazioni che precedono l’analisi vera e propria. La fase di cleaning vede anche l’implementazione di tecniche di feature engineering, che aiutano a costruire modelli di predizione più accurati.
In seguito, si fa un’analisi esplorativa dei dati per rinvenire delle prime informazioni utili e per effettuare delle analisi statistiche di base, come il calcolo dello spread, della varianza e delle deviazioni. Tipicamente questo è un processo che si ripete più di una volta. In ogni caso, è buona pratica eseguire più di un algoritmo di analisi sul dataset in modo da ottenere la miglior soluzione possibile. Il seguente diagramma mostra l’architettura di un generico progetto di data analysis.
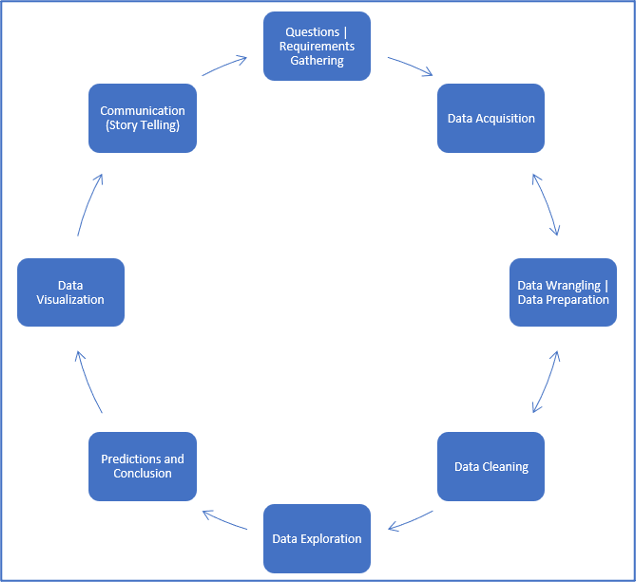 Il tipico ciclo di vita di un progetto di analisi dei dati e di implementazione di algoritmi di machine learning
Il tipico ciclo di vita di un progetto di analisi dei dati e di implementazione di algoritmi di machine learning
A proposito dei dati
Immaginiamo un compratore in cerca della propria casa dei sogni. In questo caso, esistono molteplici fattori da considerare prima di scegliere una casa. Nel dataset che useremo, proveremo a individuare i fattori più importanti che determinano la scelta d’acquisto di una casa. Vedremo come fattori come l’altezza delle fondamenta, l’altezza del soffitto o la distanza da un supermercato sono con buona probabilità meno importanti rispetto alla dimensione della casa, al prezzo per metro quadro e alla qualità del vicinato. Ugualmente il numero di stanze o la dimensione del bagno risultano essere più importanti del numero di auto che posteggiano sul vialetto. Il dataset su cui lavoreremo è composto da 79 variabili che influenzano i prezzi delle case ad Ames, in Iowa.
Riconoscimenti: l' Ames Housing dataset è una raccolta open source realizzata a scopo educativo da Dean De Cock, da non confondere col dataset Boston House Prices. Può essere piuttosto visto come un’estensione di quest’ultimo, dal momento che presenta attributi più dettagliati.
Esplorazione dei dati (Exploratory Data Analysis e Visualization)
L’analisi esplorativa dei dati è, dal punto di vista statistico, un approccio che permette di rilevare le caratteristiche principali dei dati in analisi. Questo processo include l’uso statistico di grafici, modelli e altri metodi di visualizzazione. Lo scopo principale di questa procedura è di avviare il processo di analisi dei dati andando a comprendere alcune informazioni di base, come massimi e minimi, le medie ed eventuali outlier. Questo tipo di analisi, indicato con la sigla EDA (Exploratory Data Analysis), precede i processi di analisi più dettagliati e si usa per avere una visione complessiva dei dati. Possiamo infatti dare uno sguardo alle diverse relazioni all’interno dei dati usando una combinazione di strumenti di visualizzazione e di modellazione statistica (analisi univariata, bi-variata e multivariata). Vediamo alcuni concetti generalmente usati durante l’analisi esplorativa:
- Distribuzione Normale: la distribuzione normale, anche detta curva gaussiana, è una funzione di distribuzione di probabilità che modella una distribuzione dei dati simmetrica su entrambi i lati, a destra e a sinistra della media aritmetica. Questo significa che la parte a destra dei dati è un’immagine speculare della parte a sinistra. Molti fenomeni naturali che osserviamo nel mondo reale seguono una distribuzione normale. Una derivazione importante della distribuzione normale è una regola empirica detta 3-Sigma-rule, la quale afferma che il 99,73% delle osservazioni sotto una curva normale rientra al più in 3 deviazioni standard dalla media.
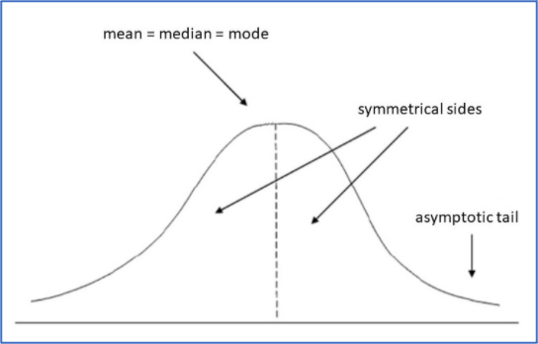
- Test di Shapiro: nella statistica, il test di Shapiro-Wilk è un test di normalità. Questo test serve a provare la validità dell’ipotesi nulla che un certo esempio è stato prelevato da un campione distribuito secondo una distribuzione normale. Il test di Shapiro rigetta l’ipotesi nulla iniziale qualora un alpha di 0.05 abbia p-value inferiore a 0.05.
- Kurtosis: il valore di Kurtosis, come il test di Shapiro, si usa per misurare la normalità dei dati. Tuttavia ha un funzionamento diverso. In sostanza Kurtosis misura la coda della distribuzione di un insieme di dati. L’interpretazione del valore di Kurtosis varia a seconda dei range di valori in cui ricade.
Andiamo a svolgere un’analisi EDA per riassumere le informazioni del nostro dataset.
# Importiamo le librerie necessarie per l’House Price Prediction
import numpy as np
import pandas as pd
import seaborn as sns
import scipy.stats as stats
from scipy.stats import norm
import statsmodels.api as sm
import matplotlib.pyplot as plt
# Importiamo il dataset di training e quello di test
housing_train_data = pd.read_csv('HousingTrain.csv')
housing_test_data = pd.read_csv('HousingTest.csv')
housing_train_data.head()
>>>
Id MSSubClass LotFrontage MSZoning LotArea LotShape Street Alley LandContour Utilities ... … PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice
0 1 060 RL 65.0 8450 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500
1 2 020 RL 81.0 9500 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500
2 3 060 RL 64.0 11351 Pave NaN IR2 Lvl…. AllPub ... 0 NaN NaN NaN 0 9 2008 WD Normal 222500
3 4 070 RL 61.0 9520 Pave NaN Reg Lvl … AllPub ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 141000
4 5 060 RL 84.0 14260 Pave NaN IR1 Lvl … AllPub ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000
5 rows × 81 columns
# Come possiamo osservare, il training set presenta 81 colonne. Il metodo head() ci mostra solo 5 righe. Per sapere qual è la dimensione totale del training set usiamo l’attributo shape come segue:
housing_train_data.shape
>>> (1460,81)
# Il training set ha 1460 righe e 81 colonne
# Come passo successivo, verifichiamo quali attributi influenzano la variabile target, il Sale Price
# Preleviamo i parametri principali della Distribuzione Normale e dalla distribuzione della variabile target
(x,y) = norm.fit(housing_train_data['SalePrice'])
plt.figure(figsize = (10,5))
sns.distplot(housing_train_data['SalePrice'], kde = True, hist=True, fit = norm)
plt.title('Distribution comparison of the Target Variable to the Normal Curve', fontsize = 10)
plt.xlabel("Sale Price of the House in dollars", fontsize = 10)
plt.show()
>>>
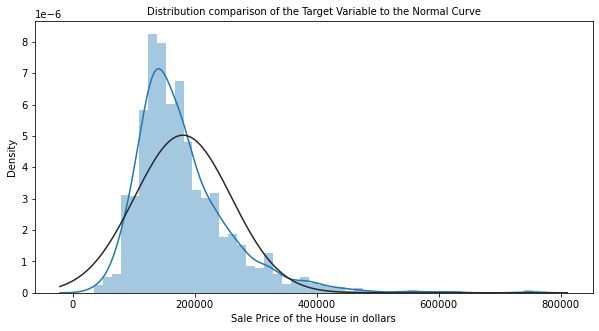
# In teoria, valori oltre 0.5 e -0.5 vengono considerati distorti, mentre Kurtosis si considera per valori oltre -2 e 2. Il grafico mostra chiaramente che la curva del prezzo di vendita non è una distribuzione gaussiana, ma che i dati hanno piuttosto un’inclinazione a destra. Osserviamo i risultati di Kurtosis e del test di Shapiro per confermare questa ipotesi.
# Verifichiamo i valori di Skewness e Kurtosis:
a,b = stats.shapiro(housing_train_data['SalePrice'])
print("Skewness Value: %f" % abs(housing_train_data['SalePrice']).skew())
print("Value of Kurtosis: %f" % abs(housing_train_data['SalePrice']).kurt())
print("Shapiro Test on A: %f" % a)
print("Shapiro Test on B: %f" % b)
>>> Skewness Value: 1.882876
>>> Value of Kurtosis: 6.536282
>>> Shapiro Test on A: 0.869672
>>> Shapiro Test on B: 0.000000
# I valori di Skewness e Kurtosis confermano la tendenza dei dati a destra, mentre il test di Shapiro conferma che non si tratta di una distribuzione normale.
# Esploriamo le singole colonne per comprendere la loro relazione con la variabile target. In particolare, vediamo quali sono gli attributi maggiormente correlate alla variabile target.
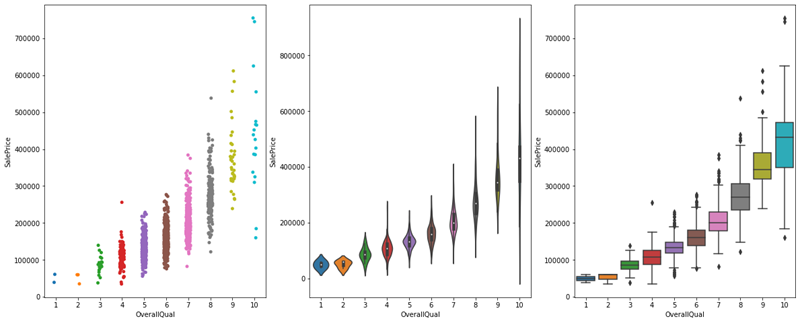
# Iniziamo dalla colonna Overall Quality che valuta la qualità dell’offerta
figs, ar = plt.subplots(1,3, figsize = (20,8))
sns.stripplot(data=housing_train_data, x = 'OverallQual', y='SalePrice', ax = ar[0])
sns.violinplot(data=housing_train_data, x = 'OverallQual', y='SalePrice', ax = ar[1])
sns.boxplot(data=housing_train_data, x = 'OverallQual', y='SalePrice', ax = ar[2])
plt.show()
>>>
# Vediamo anche qual è l’impatto del numero di stanze del piano superiore sul prezzo di vendita
figs, ar = plt.subplots(1,3, figsize = (20,8))
sns.stripplot(data=housing_train_data, x = 'TotRmsAbvGrd', y='SalePrice', ax = ar[0])
sns.violinplot(data=housing_train_data, x = 'TotRmsAbvGrd', y='SalePrice', ax = ar[1])
sns.boxplot(data=housing_train_data, x = 'TotRmsAbvGrd', y='SalePrice', ax = ar[2])
plt.show()
>>>
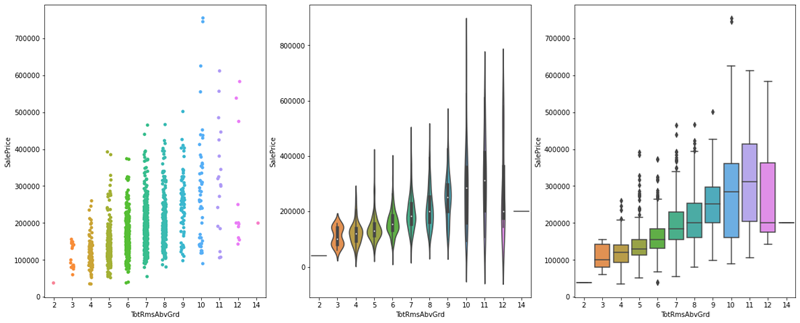
# Ora vediamo l’impatto dell’anno di costruzione dell’immobile
Year_Built_Constant = 0.56
plt.figure(figsize = (14,6))
sns.regplot(data=housing_train_data, x = 'YearBuilt', y='SalePrice', scatter_kws={'alpha':0.2})
plt.title('Build Year against Sales Price', fontsize = 12)
plt.show()
>>>
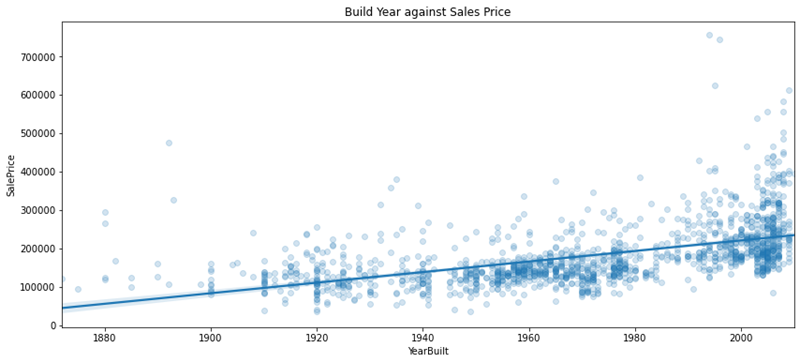
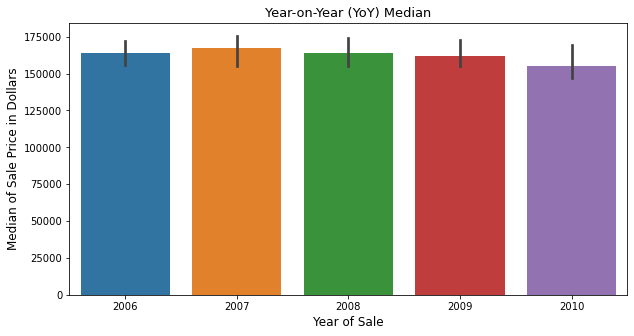
# Vediamo la mediana del prezzo di vendita anno per anno
plt.figure(figsize = (10,5))
sns.barplot(x='YrSold', y="SalePrice", data = housing_train_data, estimator = np.median)
plt.title('Year-on-Year (YoY) Median', fontsize = 13)
plt.xlabel('Year of Sale', fontsize = 12)
plt.ylabel('Median of Sale Price in Dollars', fontsize = 12)
plt.show()
>>>
# Con questo concludiamo la nostra analisi esplorativa dei dati, che ci ha portato ad avere una conoscenza già abbastanza approfondita del dataset
Riassumiamo le osservazioni chiave ottenute dall’Analisi Esplorativa:
- l’input presenta 81 colonne, o attributi, che definiscono il prezzo di vendita degli immobili;
- i test di normalità hanno mostrato che la variabile target non segue la distribuzione di Gauss. Anche il test di Shapiro ha confermato che la distrubuzione non è una normale;
- i test di Skew e Kurtosis hanno confermato le ipotesi precedenti, rivelando che i dati hanno un’inclinazione a destra;
- abbiamo constatato che il parametro “Overall Quality” ha un impatto significativo sul prezzo di vendita di un immobile;
- abbiamo anche visto che il prezzo di vendita mediano nell’arco di un lustro si aggira intorno ai 150000 dollari.
Abbiamo applicato l'EDA sul nostro dataset. Questo capitolo continua nella seconda parte dove vedremo come effettuare il pre-processing e come applicare tecniche di feature engineering prima del task di classificazione.