Implementazione Python del Time Series Forecasting
Per mettere in pratica i concetti appena presentati nell’implementazione di una serie temporale, useremo lo stesso dataset del daily climate change usato prima. Lo scopo della predizione, in questo caso, è predire i valori medi futuri di pressione dell’aria, velocità del vento ecc.
In particolare, prediremo i dati per sei intervalli di tempo futuri.
Prima di iniziare, riprendiamo alcuni ulteriori concetti per comprendere meglio il funzionamento delle serie temporali. Uno di questi è il Test Ad-Fuller o test Dickey-Fuller aumentato (ADF) il quale verifica la veridicità sull’ipotesi nulla della presenza di una radice unitaria all’interno dei dati. La statistica di questo test è sempre un numero negativo. In teoria il rifiuto dell’ipotesi nulla è tanto più forte quanto più è negativo il valore della statistica.
Un altro concetto importante è il VAR (Vector Auto Regressions). Il VAR è un modello statistico usato per studiare la relazione tra le quantità dipendenti di una serie temporale che tendono a variare nel tempo. Infine il modello multivariato di adattamento consente di usare il ritardo sulle variabili temporali e di predirne i valori in base ai ritardi in input.
# Importiamo le librerie per il preprocessing
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Il modulo Series di pandas ci aiuterà nella creazione di serie temporali
from pandas import Series,DataFrame
%matplotlib inline
# Statsmodel e Adfuller permetteranno di testare la stazionarietà delle serie
import statsmodels
from statsmodels.tsa.stattools import adfuller
time_series_train = pd.read_csv('DailyDelhiClimateTrain.csv', parse_dates=True)
time_series_train["date"] = pd.to_datetime(time_series_train["date"])
time_series_train.date.freq ="D"
time_series_train.set_index("date", inplace=True)
time_series_train.columns
>>> Index(['meantemp', 'humidity', 'wind_speed', 'meanpressure'], dtype='object')
# Scomponiamo la serie col metodo Decompose di statsmodels
from statsmodels.tsa.seasonal import seasonal_decompose
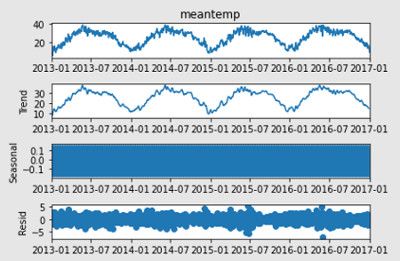
sd_1 = seasonal_decompose(time_series_train["meantemp"])
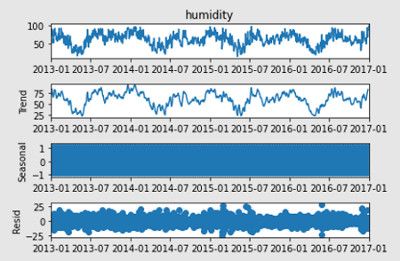
sd_2 = seasonal_decompose(time_series_train["humidity"])
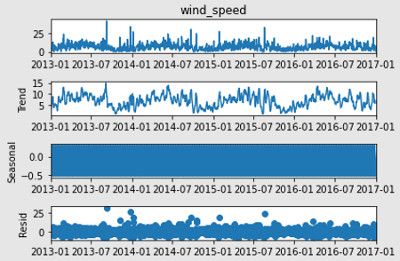
sd_3 = seasonal_decompose(time_series_train["wind_speed"])
sd_4 = seasonal_decompose(time_series_train["meanpressure"])
sd_1.plot()
sd_2.plot()
sd_3.plot()
sd_4.plot()
>>>
# Dai grafici sembra che tutti i campi, eccetto la pressione media, siano già stazionari
# Per confermare ulteriormente la stazionarietà, eseguiamo il test ad-fuller su tutte le colonne
adfuller(time_series_train["meantemp"])

 >>>
(-2.021069055920669,
0.277412137230162,
10,
1451,
{'1%': -3.4348647527922824,
'5%': -2.863533960720434,
'10%': -2.567831568508802},
5423.895746470953)
>>>
(-2.021069055920669,
0.277412137230162,
10,
1451,
{'1%': -3.4348647527922824,
'5%': -2.863533960720434,
'10%': -2.567831568508802},
5423.895746470953)
adfuller(time_series_train["humidity"])
>>>
(-3.6755769191633343,
0.004470100478130829,
15,
1446,
{'1%': -3.434880391815318,
'5%': -2.8635408625359315,
'10%': -2.5678352438452814},
9961.530007876658)
adfuller(time_series_train["wind_speed"])
>>>
(-3.838096756685103,
0.0025407221531464205,
24,
1437,
{'1%': -3.434908816804013,
'5%': -2.863553406963303,
'10%': -2.5678419239852994},
8107.698049704068)
adfuller(time_series_train["meanpressure"])
(-38.0785900255616,
0.0,
0,
1461,
{'1%': -3.434833796443757,
'5%': -2.8635202989550756,
'10%': -2.567824293398847},
19034.033348261542)
# Consolidiamo i test ad-fuller rieseguendoli su dati statici
temp_var = time_series_train.columns
print('significance level : 0.05')
for var in temp_var:
ad_full = adfuller(time_series_train[var])
print(f'For {var}')
print(f'Test static {ad_full[1]}',end='\n \n')
>>>
significance level : 0.05
For meantemp
Test static 0.277412137230162
For humidity
Test static 0.004470100478130829
For wind_speed
Test static 0.0025407221531464205
For meanpressure
Test static 0.0
# Con il test ad-fuller possiamo concludere che tutti i dati sono stazionari, dal momento che i test sono al di sotto del livello di significatività. Ciò rigetta anche l’ipotesi della non-staticità del campo meanpressure.
# Andiamo ora ad addestrare e valutare un modello di predizione
from statsmodels.tsa.vector_ar.var_model import VAR
train_model = VAR(time_series_train)
fit_model = train_model.fit(6)
# Assumiamo un lag_order pari a 6 dal momento che il valore AIC è più basso per lag_order=6
fix_train_test = time_series_train.dropna()
order_lag_a = fit_model.k_ar
X = fix_train_test[:-order_lag_a]
Y = fix_train_test[-order_lag_a:]
# Validation
validate_y = X.values[-order_lag_a:]
forcast_val = fit_model.forecast(validate_y,steps=order_lag_a)
train_forecast = DataFrame(forcast_val,index=time_series_train.index[-order_lag_a:],columns=Y.columns)
train_forecast
>>>
date meantemp humidity wind_speed meanpressure
2016-12-27 17.348792 70.642850 7.421823 1114.035254
2016-12-28 17.726869 68.599848 6.255075 1010.853957
2016-12-29 17.496228 70.909252 6.333213 992.402101
2016-12-30 17.648930 72.704921 5.795082 1004.788372
2016-12-31 17.642094 73.481324 5.946337 1031.434268
2017-01-01 17.884142 72.291600 5.717422 1026.203648
# Verifica delle performance del modello
from sklearn.metrics import mean_absolute_error
for i in time_series_train.columns:
print(f'MAE of {i} is {mean_absolute_error(Y[[i]],train_forecast[[i]])}')
>>> MAE of meantemp is 2.8822831810975056
>>> MAE of humidity is 13.130988743454763
>>> MAE of wind_speed is 1.920218001710155
>>> MAE of meanpressure is 27.450580288019903
# L’umidità e la pressione media mostrano l’errore di predizione maggiore. Potremmo assumere che ci siano dei fattori esterni che influiscono su queste misure.
# Il modello invece predice bene la velocità del vento e la temperatura medi, con un errore inferiore al 5%
# Usiamo ora il test set per fare forecasting su 6 periodi di tempo futuri
test_forecast = pd.read_csv('DailyDelhiClimateTest.csv',parse_dates=['date'])
period_range = pd.date_range('2017-01-05',periods=6)
order_lag_b = fit_model.k_ar
X1,Y1 = test_forecast[1:-order_lag_b],test_forecast[-order_lag_b:]
input_val = Y1.values[-order_lag_b:]
data_forecast = fit_model.forecast(input_val,steps=order_lag_b)
df_forecast = DataFrame(data_forecast,columns=X1.columns,index=period_range)
df_forecast
>>>
date meantemp humidity wind_speed meanpressure
2017-01-05 32.268428 29.294430 9.273689 1028.807335
2017-01-06 32.404384 33.362166 8.264082 996.529808
2017-01-07 32.420385 36.232933 8.283705 982.572684
2017-01-08 32.148770 38.216824 8.446112 997.883636
2017-01-09 32.057660 38.568787 8.467237 1020.024659
2017-01-10 32.083931 38.433189 8.478052 1037.946455
# Plottiamo i dati di test con analisi di auto correlazione
from statsmodels.graphics.tsaplots import plot_acf
# Prossimi 6 valori di temperatura media (grafico 1) e di velocità del vento (grafico 2)
plot_acf(df_forecast["meantemp"])
plot_acf(df_forecast["wind_speed"])
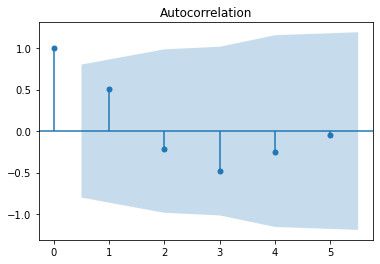
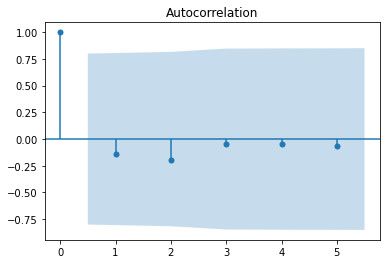
# Con questo abbiamo concluso il time series forecasting dei dati climatici giornalieri per una città.
Ora che abbiamo visto come implementare un modello predittivo sulle serie temporali, cioè per dati che cambiano nel tempo, vediamo alcuni ulteriori concetti importanti utili a migliorare l’accuratezza dei modelli.
Capire Autocorrelazione e Correlazione Parziale
Ritardi nelle serie temporali
Il termine ritardo, meglio espresso dal termine inglese lag, si riferisce appunto a un tempo di risposta più lento del solito e viene spesso chiamato anche latenza. Nell’analisi o nella predizione di una serie temporale, per dati trimestrali, ad esempio un intervallo considerato appropriato rientra nell’intervallo 1-8. Per dati mensili invece dei ritardi possono essere di 6, 12 o 24 mesi.
Per capire meglio i ritardi, consideriamo il seguente scenario: per un insieme di valori discreti appartenenti a una serie temporale, un ritardo di 1 significa che i valori della serie vengono confrontati con valori della stessa serie in istanti di tempo precedenti a quello corrente, cioè la serie viene slittata indietro di un periodo di tempo.
Autocorrelazione
L’autocorrelazione è la correlazione tra una serie e i suoi ritardi. L’autocorrelazione fa tra i valori ritardati di una serie è ciò che la normale correlazione fa tra due variabili nel calcolare l’intensità della loro relazione lineare. Se la serie è considerevolmente autocorrelata significa che i ritardi hanno un impatto elevato nelle predizioni. Più in generale un fattore di correlazione pari a 1 (Lag=1) esprime la correlazione tra valori che si trovano a un periodo di distanza tra loro. Ugualmente l’autocorrelazione di ritardo k mostra l’associazione tra valori separati tra loro da k periodi di tempo.
Partial Autocorrelation
Anche l’autocorrelazione parziale ha lo scopo di fornire informazioni sulla relazione tra una variabile e il suo ritardo. Tuttavia l’autocorrelazione parziale fornisce solo i dettagli dell’associazione pura con il ritardo e non considera correlazioni relative a ritardi intermedi.
Test di Causalità di Granger per la previsione di serie temporali
Il test di causalità di Granger aiuta a capire il comportamento di una serie analizzando serie temporali simili. Il test assume che se un certo evento X causa l’avvenimento di un altro evento Y, allora le predizioni future di Y basate sui valori precedenti di Y e X combinati dovrebbero superare le predizioni di Y basate unicamente su Y. Per questo motivo si assume che la causalità di Granger non dovrebbe essere usata nel caso in cui si considerano i valori di Y come causati da un ritardo di Y stesso.
Il pacchetto statsmodel fornisce un implementazione del test di causalità di Granger. Il metodo riceve un vettore bidimensionale e due colonne. La prima colonna contiene i valori, mentre il predittore X si trova nella seconda colonna. In questo caso l’ipotesi nulla è che la seconda colonna non provochi il verificarsi della prima colonna. L’ipotesi nulla viene rigettata se il p-value è inferiore al livello di significatività stabilito di 0.5. Questo concluderebbe anche che il ritardo di X è utile. Il secondo argomento maxlag permette di fissare il numero massimo di ritardi di Y da includere nel test.
Sperimentiamo quanto appreso implementando il test di Granger Causality per il dataset Daily Climate.
# Importiamo da statsmodel il modulo per il test di causalità di Granger e usiamo la metrica di test Chi-quadro
from statsmodels.tsa.stattools import grangercausalitytests
test_var = time_series.columns
lag_max = 12
test_type = 'ssr_chi2test'
causal_val = DataFrame(np.zeros((len(test_var),len(test_var))),columns=test_var,index=test_var)
for a in test_var:
for b in test_var:
c = grangercausalitytests ( time_series [ [b,a] ], maxlag = lag_max, verbose = False)
pred_val = [round ( c [ i +1 ] [0] [test_type] [1], 5 ) for i in range (lag_max) ]
min_value = np.min (pred_val)
causal_val.loc[b,a] = min_value
causal_val
>>>
humidity wind_speed mean pressure
meantemp 1.00000 0.00382 0.00054 0.22012
humidity 0.00000 1.00000 0.13319 0.15053
wind_speed 0.00000 0.00000 1.00000 0.52294
meanpressure 0.00633 0.43641 0.04252 1.00000
# I risultati del test di causalità di Granger evidenziano che le feature sono strettamente dipendenti le une dalle altre.
A questo punto possiamo concludere il nostro studio sulle Serie Temporali. Sebbene le "Time Series" siano un argomento molto ampio che include diversi altri aspetti particolari che non abbiamo trattato, questo capitolo può essere considerato un buon inizio nello studio di quest’area. L’analisi inizia con lo studio dei dati della serie, la verifica della stazionarietà e della stagionalità, la costruzione dei modelli predittivi e, infine, la previsione.
In arrivo…
Lo studio dei fondamenti del Machine Learning si conclude con il forecasting delle serie temporali. Riassumendo, gli algoritmi di classificazione e di clustering permettono di predire valori appartenenti ad ampi insiemi di input. La regressione aiuta nel categorizzare e nel predire variabili indipendenti a partire da variabili dipendenti. Con l’analisi delle serie temporali possiamo infine predire valori riferiti a periodi di tempo futuri in base ai dati storici.
Nella prossima sezione, costruiremo un intero progetto su un caso di studio per applicare le conoscenze apprese sugli algoritmi di machine learning.
- Pulitura e pre-processing dei dati;
- esplorazione del problema;
- risolvere un problema reale col machine learning.