Introduzione
Una Serie Temporale è una sequenza di dati definita su un intervallo temporale. Gli intervalli di tempo possono essere ore, giorni, settimane o una qualsiasi durata quantificabile. Una serie temporale è una sequenza di osservazioni campionate a intervalli regolari. Predire serie temporali significa appunto fare predizioni di eventi che si possono osservare in intervalli di tempo futuri. In questo capitolo, esploreremo il forecasting, ovvero la predizione delle Serie Temporali.
Comprendere il flusso di predizione delle Serie Temporali
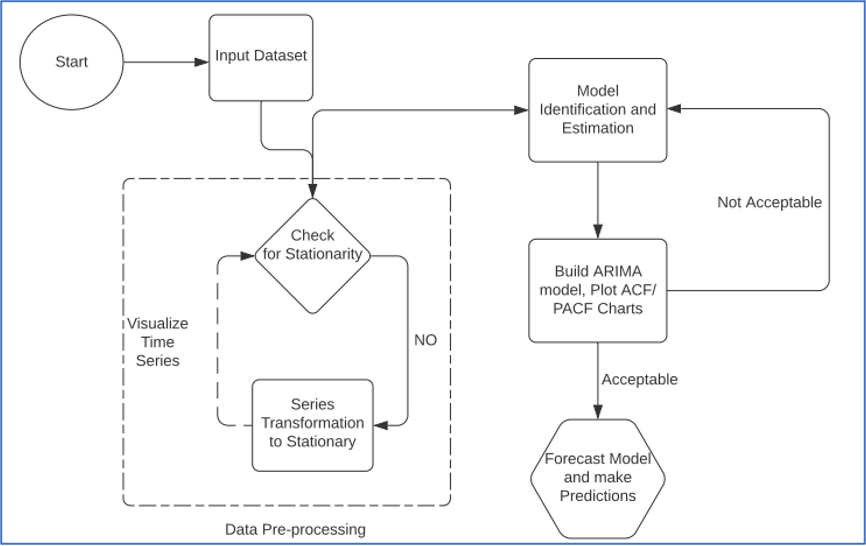
Analisi delle Sequenze
Nell’era odierna, tutte le aziende usano il Machine Learning per studiare il comportamento dei clienti e predire, ad esempio, le vendite future o le nuove acquisizioni. Inoltre la predizione delle serie temporali ha anche un’enorme importanza nel commercio e nel marketing, in quanto tutti gli aspetti rilevanti per il business di un’azienda sono, sostanzialmente, delle serie temporali, sulle quali risulta molto utile fare predizioni. Tali aspetti sono, ad esempio, la domanda, le vendite, il numero di persone che visitano un sito web, o le predizioni dei prezzi delle azioni. Per iniziare la nostra analisi, andiamo a comprendere quali sono i numerosi aspetti della natura di questi dati e della loro dipendenza dal tempo.
Dati Panel: I dati Panel, anche detti dati longitudinali, sono tipi di dati time-based che, oltre a dati sequenziali, contengono anche una o più variabili collegate che sono state osservate negli stessi periodi di tempo. Tali variabili dipendenti, naturalmente, sono molto utili a predire il valore della ‘Y’. Un modo per capire se un dataset è una serie temporale o un panel, è verificare che la colonna temporale sia l’unica componente che influisce sul risultato della predizione.
L’analisi delle serie temporali si può applicare a dati numerici continui o discreti, così come anche a dati simbolici, ovvero a successioni di caratteri, come le lettere o le parole di un linguaggio.
Pacchetti e librerie Python per l’analisi di Serie Temporali
Diamo un’occhiata ad alcune librerie e funzionalità importanti per analizzare le serie temporali e costruire modelli predittivi:
- Stattools: è un pacchetto di PyPi che implementa lo Statistical learning e numerosi algoritmi per fare inferenza sui dati. È supportato dalle versioni 3.6 e successive di Python.
- Pandas Dataframe Resample: Il ricampionamento è una tecnica che si impiega per modificare la frequenza delle osservazioni all’interno di serie temporali. I Dataframe di Pandas offrono dei metodi di resampling convenienti per la riconversione di frequenza. Gli oggetti da ricampionare devono essere in formato di data (datetime, datetimeindex, periodindex, timedeltaindex, ecc…). Esistono due tipi di resampling:
- Upsampling: in questo caso viene aumentata la frequenza degli esempi. Ad esempio, si modifica la frequenza da minuti a secondi.
- Downsampling: è il contrario dell’upsampling. Ad esempio, si modifica la frequenza da giorni a mesi.
- pmdarima: in origine pyramid-arima, pmdarima è una libreria di statistica che aiuta a effettuare il filling dei dati in serie temporali cioè riempire dati mancanti. La libreria contiene metodi per effettuare test di validità statistica per verificare la stazionarietà e la stagionalità dei dati. Include anche funzionalità come la differenziazione e la differenziazione inversa delle serie temporali.
# Importiamo le librerie per il pre-processing
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Il modulo Series di Pandas aiuterà a creare una serie temporale
from pandas import Series,DataFrame
import seaborn as sns
%matplotlib inline
# Dataset (Dove trovarlo: https://www.kaggle.com/sumanthvrao/daily-climate-time-series-data)
# Si vuole predire il clima giornaliero di una città dell’India
time_series = pd.read_csv('DailyDelhiClimateTrain.csv', parse_dates=['date'], index_col='date')
time_series.head()
>>>
meantemp humidity wind_speed meanpressure
date
2013-01-01 10.000000 84.500000 0.000000 1015.666667
2013-01-02 7.400000 92.000000 2.980000 1017.800000
2013-01-03 7.166667 87.000000 4.633333 1018.666667
2013-01-04 8.666667 71.333333 1.233333 1017.166667
2013-01-05 6.000000 86.833333 3.700000 1016.500000
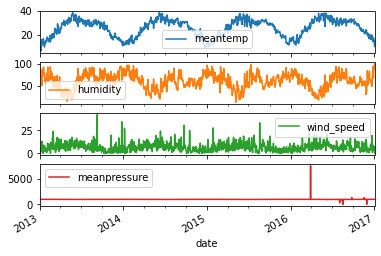
# Vediamo un po’ di metodi statistici per osservare schemi nei dati
# Plottiamo le single colonne
time_series.plot(subplots=True)
>>>
array([, ,
, ],
dtype=object)
# Calcoliamo la media, i massimi e i minimi per ogni colonna
time_series.mean()
>>>
meantemp 25.495521
humidity 60.771702
wind_speed 6.802209
meanpressure 1011.104548
dtype: float64
time_series.max()
>>>
meantemp 38.714286
humidity 100.000000
wind_speed 42.220000
meanpressure 7679.333333
dtype: float64
time_series.min()
>>>
meantemp 6.000000
humidity 13.428571
wind_speed 0.000000
meanpressure -3.041667
dtype: float64
# Il metodo describe() per ogni colonna fornisce informazioni come conteggio, media, deviazioni e quantili
time_series.describe()
>>>
meantemp humidity wind_speed meanpressure
count 1462.000000 1462.000000 1462.000000 1462.000000
mean 25.495521 60.771702 6.802209 1011.104548
std 7.348103 16.769652 4.561602 180.231668
min 6.000000 13.428571 0.000000 -3.041667
25% 18.857143 50.375000 3.475000 1001.580357
50% 27.714286 62.625000 6.221667 1008.563492
75% 31.305804 72.218750 9.238235 1014.944901
max 38.714286 100.000000 42.220000 7679.333333
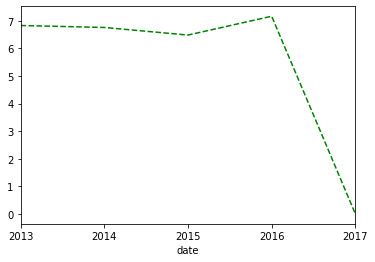
# Resampling del dataset col metodo mean()
timeseries_mm = time_series['wind_speed'].resample("A").mean()
timeseries_mm.plot(style='g--')
plt.show()
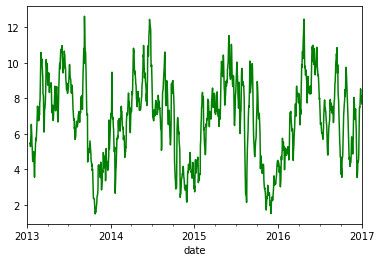
# Calcolo della media mobile con intervalli di tempo di dimensione 14
time_series['wind_speed'].rolling(window=14, center=False).mean().plot(style='-g')
plt.show()
>>>
# Nella prossima sezione implementeremo un modello per la predizione di serie temporali su questo dataset
Serie Stazionarie e Non-Stazionarie
Una caratteristica di ogni serie temporale è la stazionarietà. Nel caso di serie stazionarie, i valori della serie temporale non sono funzione del tempo. Questo vuol dire che le misure come la media, la varianza o l’autocorrelazione dei valori correnti con quelli passati sono costanti nel tempo. Inoltre una serie stazionaria non è soggetta a mutamenti stagionali. È possibile rendere stazionarie quasi tutte le serie temporali, applicando trasformazioni appropriate.
Come rendere stazionaria una serie temporale
Le serie temporali possono essere rese stazionarie usando uno dei seguenti metodi:
- differenziare una o più volte la serie: la differenziazione è il concetto secondo il quale fare la sottrazione tra il valore corrente di una serie e un valore precedente della stessa serie renda tale valore stazionario. Differenziazione significa quindi sottrarre osservazioni consecutive di una serie.
Ad esempio, consideriamo la seguente serie: [1, 5, 2, 12, 20]. Il risultato di una differenziazione è: [5-1, 2-5, 12-2, 20-12] = [4, -3, 10, 8]. La seconda differenziazione invece darà: [-3-4, -10-3, 8-10] = [-7, -13, -2];
- prendere il logaritmo della serie;
- prendere la radice N-esima della serie;
- combinare una o più delle tecniche precedenti.
Perché le serie stazionarie sono importanti?
Una serie temporale stazionaria è molto più affidabile e facile da predire rispetto ad altre. Il motivo principale è che i modelli predittivi sulle serie temporali si basano fondamentalmente su algoritmi di regressione lineare, i quali sfruttano i ritardi dei dati in serie per formare i predittori.
Inoltre, sappiamo che gli algoritmi di regressione lineare lavorano meglio in contesti in cui i predittori (X) non sono correlati tra loro. Rendere una serie stazionaria significa rimuovere tutte le correlazioni tra predittori e, quindi, rendere la serie più adatta ad applicare la regressione. Una volta che i predittori, o i ritardi, della serie sono stati resi indipendenti, ci si aspetta di avere predizioni più affidabili.
Stagionalità e trattamento dei dati mancanti
Nelle serie temporali, la stagionalità nei dati è la presenza di variazioni che si verificano a intervalli di tempo specifici inferiori a un anno. Questi intervalli possono essere orari, mensili, settimanali o quadrimestrali. Diversi aspetti possono causare stagionalità, come ad esempio i cambiamenti climatici o il meteo. Questi aspetti, infatti, sono sempre ciclici e si verificano a intervalli regolari. Comprendere la stagionalità è molto importante per quelle aziende il cui business dipende dalle variazioni, come i mercati azionari, le organizzazioni lavorative, ecc.
Le variazioni stagionali hanno diversi significati e si studiano per svariate ragioni:
- spiegare gli effetti stagionali su un insieme di dati permette di avere una comprensione dettagliata dell’impatto che il cambio di stagione ha sui dati;
- una volta determinato lo schema stagionale, è possibile applicare delle metodologie per estrapolarlo dalla serie temporale. Questo aiuta a studiare gli effetti delle altre componenti del dataset che hanno natura irregolare. Il processo di eliminazione della stagionalità è detto destagionalizzazione;
- la storia dei pattern di stagionalità aiuta a predire le tendenze future di dati simili. È il caso, ad esempio, dei pattern climatici.
Trattamento dei valori mancanti nelle Time Series
In un qualsiasi dataset, capita spesso di riscontrare dati mancanti. Allo stesso modo, all’interno di dati in serie temporale possono mancare date o intervalli di tempo. Tali mancanze denotano il fatto che non è stato catturato alcun dato in un particolare periodo di tempo oppure che il dato non era disponibile in quel momento. Inoltre è sempre possibile osservare dati con valore nullo. In questo caso bisogna ignorare i falsi negativi. Un altro aspetto importante è che non è buona pratica usare la media e la mediana per riempire i dati mancanti in una serie temporale, specialmente nel caso in cui i dati non evidenziano stazionarietà. Una scelta migliore e maggiormente sensata potrebbe invece essere quella di riempire i dati futuri con valori storici di quel lasso di tempo.
Comunque, si possono sperimentare diversi approcci per attribuire valori ai dati mancanti, in base allo studio dei dati temporali e del panorama della serie. Alcune tecniche comuni e degne di nota sono:
- Backward Fill;
- Interpolazione lineare;
- Interpolazione quadratica;
- Media dei nearest neighbor;
- Media stagionale delle controparti.
Inoltre, è importante misurare le prestazioni della serie temporale dopo aver introdotto i nuovi valori. Questa è una buona pratica in quanto, dopo aver testato due o più metodi di riempimento, si va a calcolare l’accuratezza del modello usando ad esempio il Root Mean Squared Error (RMSE) per decidere quale tecnica si adatta meglio ai dati.
Questo capitolo continua nella seconda parte.