Regressione multipla
La regressione, quando eseguita con più variabili indipendenti è vista come un modello di regressione in più variabili.
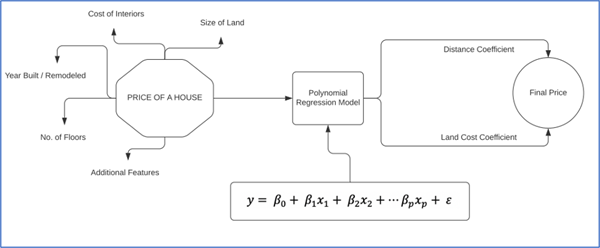 Rappresentazione di un’analisi di regressione in più variabili per la predizione del prezzo di una casa sulla base dei fattori esterni che determinano il prezzo in una certa area, dati due coefficienti costanti.
Rappresentazione di un’analisi di regressione in più variabili per la predizione del prezzo di una casa sulla base dei fattori esterni che determinano il prezzo in una certa area, dati due coefficienti costanti.
# Utilizziamo lo stesso dataset per applicare la regressione in più variabili
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
input_data=input_data[['Species','Length1','Length2','Length3','Height','Width','Weight']]
y_axis = input_data.Weight.values.reshape(–1,1)
x_axis = input_data.Width.values.reshape(–1,1)
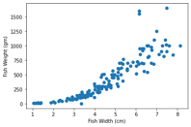
plt.scatter(x_axis,y_axis)
plt.ylabel("weight of fish in Gram")
plt.xlabel("diagonal width in cm")
>>>
Text(0.5, 0, 'Fish Width (cm)')
>>>
Text(0.5, 0, 'Fish Width (cm)')
 # Addestriamo il modello di regressione lineare e verifichiamo la precision del modello
lin_reg = LinearRegression()
lin_reg.fit(x_axis,y_axis)
y_head = lin_reg.predict(x_axis)
plt.plot(x_axis,y_head, color="red", label="linear")
plt.show()
print("Fish in the 750 Gm Weight ", lin_reg.predict([[750]]))
# Addestriamo il modello di regressione lineare e verifichiamo la precision del modello
lin_reg = LinearRegression()
lin_reg.fit(x_axis,y_axis)
y_head = lin_reg.predict(x_axis)
plt.plot(x_axis,y_head, color="red", label="linear")
plt.show()
print("Fish in the 750 Gm Weight ", lin_reg.predict([[750]]))
>>> .png.aspx;)
>>> Fish in the 750 Gm Weight [[140753.16]]
# Effettuiamo un preprocessing usando la regressione polinomiale
# Usiamo un polinomio di secondo grado
poly_reg = PolynomialFeatures(degree = 2)
x_poly = poly_reg.fit_transform(x_axis)
lin_reg_two = LinearRegression()
lin_reg_two.fit(x_poly,y_axis)
y_head_two = lin_reg_two.predict(x_poly)
plt.plot(x_axis,y_head_two,color="blue",label="Polynomial Distribution")
plt.legend()
plt.show()
# Il grafico mostra la distribuzione polinomiale dei dati in più variabili
>>>
 # Stampiamo i valori predetti e confrontiamoli con quelli di training
for i in range(0,158):
print(y_axis[i], y_head_two[i])
>>>
[242.] [266.4]
[290.] [316.99]
[340.] [391.83]
[363.] [344.95]
[430.] [483.53]
[450.] [439.24]
[500.] [515.6]
[390.] [390.61]
[450.] [421.84]
[500.] [445.98]
[475.] [477.03]
[500.] [415.84]
[500.] [328.51]
[340.] [470.22]
[600.] [491.61]
[600.] [585.38]
[700.] [517.15]
# Stampiamo i valori predetti e confrontiamoli con quelli di training
for i in range(0,158):
print(y_axis[i], y_head_two[i])
>>>
[242.] [266.4]
[290.] [316.99]
[340.] [391.83]
[363.] [344.95]
[430.] [483.53]
[450.] [439.24]
[500.] [515.6]
[390.] [390.61]
[450.] [421.84]
[500.] [445.98]
[475.] [477.03]
[500.] [415.84]
[500.] [328.51]
[340.] [470.22]
[600.] [491.61]
[600.] [585.38]
[700.] [517.15]
# Nella prossima sezione discutiamo le metriche di valutazione
Performance degli algoritmi di regressione
Finora abbiamo visto come vengono adoperati gli algoritmi di regressione lineare e multivariata per trovare le correlazioni tra le variabili di input e di output all’interno di un set di dati. Per concludere, vediamo una panoramica delle metriche di valutazione per questi algoritmi.
- Metriche di Scikit-Learn: il modulo sklearn.metrics offre molte funzioni per misurare l’accuratezza di modelli addestrati per il clustering, la classificazione e la regressione. Esistono diverse API usate da questo modulo come Estimator, Scoring e Metric. Il pacchetto Estimator usa criteri di valutazione standard come meccanismo di confronto. I risultati vengono valutati secondo questi criteri e viene rilasciato uno score. Il pacchetto Scoring invece, per calcolare la similarità tra i risultati predetti e quelli attesi, offre strumenti come la cross-validation. Le funzioni del pacchetto Metric invece implementano altre metriche per scopi specifici.
- Mean Squared Error: si esprime come la media delle radici quadrate dei singoli errori, cioè è la radice quadrata della media delle differenze tra i valori stimati e i valori osservati. Non esiste un valore ideale di MSE, comunque, più è vicino a 0 e migliore sarà la qualità del modello. Il valore 0 denota il modello perfetto e non è raggiungibile nei casi reali.
- Explained Variance Score: misura la dispersione totale, o la varianza matematica, calcolata sulle predizioni. La parte complementare della EV è detta varianza inspiegabile o residua e definisce una misura di errore. Un’alta percentuale di Explained Variance indica una buona forza di associazione.
- R2 Score (Coefficiente di Determinazione): l’R-squared score è la frazione di varianza che occorre nella variabile dipendente che è predicibile dalle variabili indipendenti. In generale, un valore basso di R2 indica un buon modello, mentre alti valori di R2 indicano che il modello non si adatta bene ai dati.
Score di valutazione per un Regressore Lineare
import sklearn.metrics as sm
print("Measuring the Performance of this Linear regressor:")
print("The Mean absolute error is", round(sm.mean_absolute_error(y_test, y_pred), 2))
print("The Mean squared error is", round(sm.mean_squared_error(y_test, y_pred), 2))
print("The Median absolute error is", round(sm.median_absolute_error(y_test, y_pred), 2))
print("The Explain variance score is", round(sm.explained_variance_score(y_test, y_pred), 2))
print("The R2 score is", round(sm.r2_score(y_test, y_pred), 2))
>>> Measuring the Performance of this Linear regressor:
>>> The Mean absolute error is 2.43
>>> The Mean squared error is 9.47
>>> The Median absolute error is 2.22
>>> The Explain variance score is 0.99
>>> The R2 score is 0.98
Score di valutazione per un Regressore Multivariato
print("Measuring the Performance of this Linear regressor:")
print("The Mean absolute error is", round(sm.mean_absolute_error(y_axis, y_head_two), 2))
print("The Mean squared error is", round(sm.mean_squared_error(y_axis, y_head_two), 2))
print("The Median absolute error is", round(sm.median_absolute_error(y_axis, y_head_two), 2))
print("The Explain variance score is", round(sm.explained_variance_score(y_axis, y_head_two), 2))
print("The R2 score is", round(sm.r2_score(y_axis, y_head_two), 2))
>>> Measuring the Performance of this Polynomial Regressor:
>>> The Mean absolute error is 91.77
>>> The Mean squared error is 21967.53
>>> The Median absolute error is 57.4
>>> The Explain variance score is 0.83
>>> The R2 score is 0.83
Cosa scegliere tra Classificazione, Clustering e Regressione
Ora che conosciamo le funzionalità e gli utilizzi della classificazione, del clustering e della regressione, è tempo di capire quale algoritmo di Machine Learning scegliere per un dato problema. I modelli di regressione vengono usati per predire valori continui, ad esempio, il numero di vendite previste per una giornata, oppure le temperature di una città. Questi valori sono continui e generalmente dipendono da un flusso di variabili indipendenti. La regressione si usa quindi per definire una distribuzione polinomiale che modelli le relazioni tra variabili dipendenti e indipendenti.
Gli algoritmi di classificazione invece si usano per fare predizioni di valori discreti. Gli algoritmi come gli alberi decisionali sono usati per distinguere i dati in gruppi e sono una forma di apprendimento supervisionato. In particolare, gli alberi decisionali sono detti “Eager Learners”, cioè impazienti, in quanto si concentrano sulla comprensione delle etichette dei dati e continuano ad apprendere sempre più informazioni per raffinare le predizioni.
Gli algoritmi di clustering, infine, fanno ciò che fanno i classificatori ma con dati non etichettati. Quindi questo significa che l’algoritmo costruisce prima una sorta di modello di classificazione sul training set e poi assegna le etichette ai dati, in modo da poter etichettare in maniera corretta i dati di test. Il clustering, essendo un meccanismo non supervisionato, non può essere usato direttamente per predire dei risultati; viene generalmente usato per trovare aspetti di similarità tra i dati e raggruppare questi ultimi sulla base delle caratteristiche simili.
Prossimamente
Con la regressione, abbiamo finito di esaminare le tre principali categorie di algoritmi usati per effettuare predizioni e raggruppamenti di dati. Sebbene questi algoritmi abbiano utilizzi differenti, è sempre buon uso sperimentare diversi algoritmi sui dati per trovare quello che si adatta meglio.
Nel prossimo capitolo ci concentreremo sull’analisi delle sequenze di dati temporali e effettueremo predizioni su di esse esplorando le serie temporali e i dati sequenziali.
- Predizioni su serie temporali
- Analisi dei trend e della stagionalità
- Implementare modelli di predizione di serie temporali in Python