Regression
In questo percorso di apprendimento, finora, abbiamo connesso programmazione, matematica e analisi statistica per mettere insieme le fondamenta per il Machine Learning (ML). In questo capitolo studieremo la Regressione applicata al Machine Learning.
Analisi dei dati basata sulla Regressione
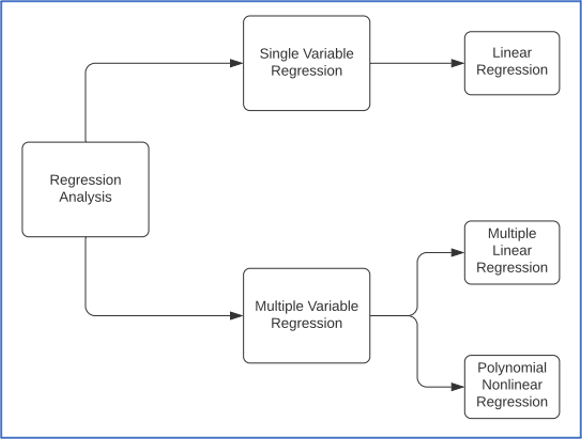
L’analisi di regressione è un insieme di tecniche statistiche che vengono usate per stimare le relazioni tra una singola variabile dipendente e una o più variabili indipendenti. Oltre che per classificare i dati, l’analisi di regressione viene usata anche per stimare la forza delle relazioni tra le variabili ed è anche utile a costruire previsioni per i valori futuri di queste variabili.
Non-collinearità: Nell’analisi di regressione ci si aspetta che le variabili indipendenti presentino tra loro un grado minimo di correlazione. Inoltre, anche nel caso in cui queste esibiscano una correlazione molto elevata, diventa piuttosto difficile valutare quali siano le reali relazioni che sussistono tra di loro. Pertanto, un requisito obbligatorio per la buona riuscita di un’analisi di regressione è la minimizzazione della collinearità tra variabili indipendenti.
Regressione lineare a singola variabile
Espressione: Y = a + bX + epsilon, dove
Y – Variabile dipendente
X – Variabile indipendente o esplicativa
a – Intercetta
b – Pendenza
epsilon – Errore
REGRESSIONE MULTIVARIATA
Espressione: Y = a + bX1 + cX2 + dX3 + epsilon, dove
Y – Variabile dipendente
X1, X2, X3 – Variabili indipendenti o esplicative
a – Intercetta
b, c, d – Pendenze
epsilon – Errore
Modelli Ensemble
I metodi Ensemble sono tecniche statistiche che prevedono l’applicazione di più algoritmi di apprendimento al fine di migliorare i risultati predetti dai dati in ingresso, rispetto a un modello preso singolarmente. A differenza delle tradizionali tecniche ensemble statistiche, i modelli di machine learning lavorano con un numero limitato di modelli specifici.
Vediamo un esempio per capire il funzionamento dei modelli Ensemble. Quando si vuole acquistare un’auto è molto difficile che si scelga di acquistare la prima auto vista. Al contrario preferiamo valutare varie alternative e diverse fonti per comprendere bene le differenze tra le auto in modo da scegliere la migliore, cioè quella che si adatta meglio alle nostre esigenze. La stessa cosa viene fatta dagli algoritmi Ensemble di Machine Learning durante l’addestramento, sia per modelli di classificazione che di regressione.
Apprendimento supervisionato e importanza dell’Ensemble
Gli algoritmi di apprendimento supervisionato si muovono all’interno di uno spazio d’ipotesi predefinito per apprendere gli input e gli output e per generare i risultati. I modelli ensemble, nella ricerca di risultati migliori, combinano insieme più classi d’ipotesi.
Tecniche Ensemble
Vediamo le principali metodologie di implementazione delle tecniche ensemble negli algoritmi di ML.
- Voto di maggioranza: questo metodo viene usato solitamente per i problemi di classificazione, dove si vanno a considerare più scenari predittivi. La predizione di ogni singolo modello è un “voto” e come output finale dell’ensemble si sceglie il voto di maggioranza, cioè il valore che è stato predetto dal maggior numero di modelli.
- Media: come suggerisce anche il nome, si usa il problema del calcolo della media e si considerano quindi algoritmi diversi per ottenere più predizioni per il problema. Infine, si prende come risultato la media di queste predizioni.
- Media ponderata: un’estensione della tecnica della media è quella della media pesata. A ogni singola predizione viene assegnato un peso di importanza. Ad esempio, se un risultato sperimentale è dato da un docente esperto in un certo campo di ricerca, il suo valore avrà un peso sicuramente maggiore rispetto al risultato di qualcuno che è nuovo in quel campo. Allo stesso modo si pesano i risultati dei modelli di ensemble in base alla conoscenza a priori che abbiamo sulla loro affidabilità.
Vediamo come implementare le tecniche Ensemble in Python:
# Consideriamo un dataset di training e usiamo 3 tecniche diverse – Decision Tree, KNN e Regressione logistica
model_one = sklearn.tree.DecisionTreeClassifier()
model_two = sklearn.neighbors.KNeighborsClassifier()
model_three = sklearn.linear_model.LogisticRegression()
# Fittiamo i tre modelli sugli stessi dati e calcoliamo separatamente i risultati
model_one.fit(x_train,y_train)
model_two.fit(x_train,y_train)
model_three.fit(x_train,y_train)
prediction_one = model_one.predict(x_test)
prediction_two = model_two.predict(x_test)
prediction_three = model_three.predict(x_test)
# Un modo per usare l’algoritmo max voting è di usare la moda dei risultati
from statistics import mode
final_pred = np.array([])
for i in range(0,len(x_test)):
final_pred = np.append(final_pred, mode([pred1[i], pred2[i], pred3[i]]))
# Anche scikit–learn fornisce un metodo VotingClassifier() per effettuale il max voting
# Il VotingClassifier è un classificatore “soft” di voto/maggioranza per estimatori non corretti
# Variabile estimators, sono liste di tuple (str, estimator) – quando si chiama il metodo VotingClassifier(), all’interno degli attributi di classe vengono memorizzate le copie degli estimatori originali
# Variabile voting {'hard', 'soft'}, default = 'hard' – ha due possibili argomenti. Per ottenere il voto di maggioranza, hard utilizza le etichette attese delle classi, mentre soft utilizza l'argmax delle probabilità predette e genera le etichette per le classi.
from sklearn.ensemble import VotingClassifier
model_one = LogisticRegression(random_state=2)
model_two = tree.DecisionTreeClassifier(random_state=2)
model_final = VotingClassifier(estimators=[('lr', model_one), ('dt', model_two)], voting='hard')
model_final.fit(x_train,y_train)
model_final.score(x_test,y_test)
# Per calcolare la media del modello ensemble, prendiamo i 3 risultati dei 3 diversi modelli e calcoliamone la media
final_prediction=(prediction_one + prediction_two + prediction_three) / 3
# In maniera simile, per calcolare la media pesata, assegnamo dei pesi ai risultati e poi facciamo la media
final_prediction=(prediction_one * 0.3 + prediction_two * 0.4 + prediction_three * 0.7)
I modelli Ensemble sono utili nell’analisi di regressione in quanto modellano lo scenario migliore e calcolano le predizioni combinando i risultati di più modelli.
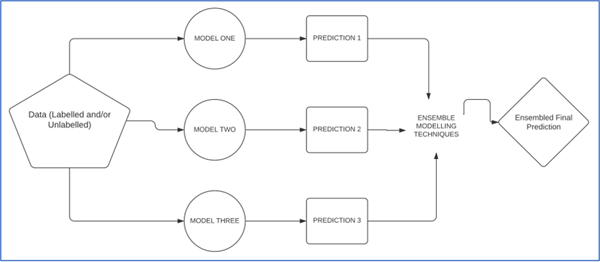 Rappresentazione dell’Ensemble
Rappresentazione dell’Ensemble
Le tecniche Ensemble usano una combinazione di più algoritmi di addestramento e delle rispettive predizioni per costruire la proiezione migliore e più adeguata possibile per i dati di test.
Algoritmi di Regressione per il Machine Learning
Per implementare gli algoritmi di regressione in Python useremo la libreria scikit-learn, già usata in precedenza per costruire i classificatori. Vediamo alcune importanti funzioni che ci serviranno per costruire un regressore.
- Regressore Lineare: la regressione lineare, o regressione singola, tenta di costruire un grafico lineare con due variabili, e viene usata per determinare le relazioni concrete tra le due variabili. Un algoritmo di regressione lineare in sostanza traccia la retta che si avvicina di più ai punti su entrambi gli assi. Per determinare la funzione della retta si calcolano la pendenza e l’intercetta, in modo da minimizzare l’errore.
Uso della regressione lineare nella vita reale: quando ad esempio si vuole predire l’erosione del suolo, esistono diversi fattori esterni, come le variazioni di temperatura e l’attraversamento degli animali, che però non incidono in maniera significativa. Ciò che invece ha una relazione diretta con l’erosione del suolo sono le precipitazioni. Dunque, la regressione lineare permette di predire i livelli di erosione del suolo in base alle precipitazioni.
- Regressore Multivariato: quando le variabili indipendenti sono più di una, si usano algoritmi di regressione multipla, che possono essere lineari o non lineari. Questo tipo di regressione si basa sull’assunzione che esista una qualche relazione tra le variabili indipendenti e la variabile dipendente incognita.
Uso della regressione multipla nella vita reale: nella medicina, è importante predire le variazioni di pressione sanguigna nei pazienti, per comprendere diverse malattie. La predizione della pressione sanguigna è un esempio di regressione multipla. Infatti, per predire la pressione sanguigna di un campione di popolazione, si mette in relazione la variabile dipendente (pressione sanguigna) con le variabili indipendenti che possono determinarla, come l’altezza, il peso, l’età, il genere e le ore settimanali di esercizio fisico.
Implementare la Regressione in Python
Per implementare gli algoritmi di regressione con Python, continuiamo a usare la libreria scikit-learn. Ecco alcune funzioni importanti per la costruzione di questi algoritmi.
Regressione Lineare:
# L’obiettivo di questo modello di regressione lineare è di predire il peso di varie specie di pesci in un negozio
# Usiamo il Fish Market dataset di Kaggle
# Link – (https://www.kaggle.com/burhanuddinraja/best–fish–from–the–data)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Importiamo il csv ed esportiamo il dataset
input_data = pd.read_csv('Fish.csv')
input_data.head()
input_data.info()
input_data.describe()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 159 entries, 0 to 158
Data columns (total 7 columns):
# Column Non–Null Count Dtype
––– –––––– –––––––––––––– –––––
0 Species 159 non–null object
1 Weight 159 non–null float64
2 Length1 159 non–null float64
3 Length2 159 non–null float64
4 Length3 159 non–null float64
5 Height 159 non–null float64
6 Width 159 non–null float64
dtypes: float64(6), object(1)
memory usage: 8.8+ KB
>>>
Weight Length1 Length2 Length3 Height Width
count 159.000000 159.000000 159.000000 159.000000 159.000000 159.000000
mean 398.326415 26.247170 28.415723 31.227044 8.970994 4.417486
std 357.978317 9.996441 10.716328 11.610246 4.286208 1.685804
min 0.000000 7.500000 8.400000 8.800000 1.728400 1.047600
25% 120.000000 19.050000 21.000000 23.150000 5.944800 3.385650
50% 273.000000 25.200000 27.300000 29.400000 7.786000 4.248500
75% 650.000000 32.700000 35.500000 39.650000 12.365900 5.584500
max 1650.000000 59.000000 63.400000 68.000000 18.957000 8.142000
input_data=input_data[['Species','Length1','Length2','Length3','Height','Width','Weight']]
input_data.head()
>>>
Species Length1 Length2 Length3 Height Width Weight
0 Bream 23.2 25.4 30.0 11.5200 4.0200 242.0
1 Bream 24.0 26.3 31.2 12.4800 4.3056 290.0
2 Bream 23.9 26.5 31.1 12.3778 4.6961 340.0
3 Bream 26.3 29.0 33.5 12.7300 4.4555 363.0
4 Bream 26.5 29.0 34.0 12.4440 5.1340 430.0
# Selezioniamo le righe e le colonne per l’etichettatura
x_axis = input_data.iloc[:,:–1]
y_axis = input_data.iloc[:,–1]
# Per rappresentare numericamente i dati categorici, importiamo il One Hot Encoder di sklearn
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
col_trans = ColumnTransformer(transformers=[('encoder',OneHotEncoder(),[0])],remainder='passthrough')
x_axis = np.array(col_trans.fit_transform(x_axis))
print(x_axis)
# Splittiamo il dataset e addestriamo un regressore lineare sui dati di training
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_axis, y_axis, test_size=0.33, random_state = 2)
from sklearn.linear_model import LinearRegression
lin_regressor = LinearRegression()
lin_regressor.fit(x_train, y_train)
# Usiamo il modello addestrato per predire i valori di y dal test set e stampiamo i pesi predetti
y_pred = lin_regressor.predict(x_test)
y_pred
>>>
array([62.62, 53.41, 7.73, 61.65, 50.09, 65.8 , 52.7 , 97.17, 90.23,
67.31, 97.52, 82.12, 72.39, 32.28, 31.12, 35.78, 58.51, 76.83,
76.07, 58.52, 25.79, 7.95, 41.28, 26.68, 79.01, 59.79, 33.98,
31.34, 35.74, 50.51, 96.57, 68.57, 92.2 , 64.9 , 32.69, 42.17,
86.01, 69.66, 31.41, 41.04, 7.4 , 29.87, 48.52, 22.6 , 8.38,
74.9 , 79.01, 66.9 , 48.02, 82.43, 30.17, 46.04, 78.89])
# Tracciamo le rette per mappare l’input nell’output
plt.scatter(x_test[:,0], y_test, color='blue')
plt.plot(x_test[:,0], y_pred, color='green', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
>>>

Nella seconda parte di questo capitolo continuiamo la nostra esposizione della Regressione.