Preprocessing dei dati e Feature Engineering
Il preprocessing dei dati, anche detto data preparation, è un passaggio vitale del processo di analisi. Si può affermare che quasi tutti i dataset abbiano delle discrepanze che possono portare a predizioni sbagliate. Quindi, prima di andare a costruire eventuali nuovi attributi a partire dai dati in input, è importante standardizzare questi dati per prepararli alle analisi successive. In seguito, vendiamo alcuni passaggi importanti da svolgere durante la fase di preparazione.
- Analisi e trattamento dei valori “NaN”: innanzitutto, è importante capire la quantità di valori NaN presenti nel dataset. Un NaN è un valore non reale che non ha una forma definita. Si verifica se un attributo è stato calcolato male o se è stato osservato erroneamente, oppure se il dato è mancante, e per altre varie ragioni. I valori NaN possono influire negativamente sui risultati dell’analisi dei dati, anche in maniera significativa.
- Dummy Encoding dei valori categorici: le variabili categoriche presenti nei dati sono spesso stringhe che, tipicamente, gli algoritmi di apprendimento non sono in grado di processare. Una parte importante del preprocessing è infatti proprio il trattamento di questi dati categorici tramite la creazione di dati “dummies”. Una codifica dummy funziona più o meno in questo modo: se, ad esempio, la categoria “Genere” ha valori definiti come “Maschio” e “Femmina”, allora un dummy encoding crea una nuova colonna per il genere che marca tutti i valori “Maschio” con 0 e tutti i valori “Femmina” con 1. In questo modo si semplifica il processo di apprendimento.
Feature Engineering
L’analisi dei dati richiede che le variabili di input si possano comparare tra loro. Se abbiamo informazioni troppo diverse che non possano essere collegate in qualche modo, gli algoritmi di learning non funzionano bene, dal momento che non avrebbero delle basi su cui valutare le predizioni. Il processo di Feature Engineering, o Representation Learning, è una procedura manuale che si attua per standardizzare e connettere tra loro degli attributi richiesti di un dataset. Questo processo è di supporto agli algoritmi di machine learning nel migliorare le performance di apprendimento e nell’aumentare la precisione dei risultati. Nelle prossime sezioni, discuteremo alcuni metodi per implementare la feature engineering nei dati.
Feature Scaling: solitamente, i dataset sono composti da dati largamente distribuiti sia in profondità che in ampiezza. Gli algoritmi di Machine Learning (ML) hanno tuttavia difficoltà a lavorare con intervalli di valori troppo grandi. Pertanto è importante ridimensionare gli attributi del dataset su una scala di valori standardizzata. Possiamo facilmente ridimensionare le features del dataset in intervalli definiti usando delle tecniche comuni, come la Standardizzazione e la Normalizzazione, in modo da migliorare le performance degli algoritmi di ML.
- Standardizzazione: La standardizzazione viene comunemente usata come tecnica per convertire i dati in una scala standard di valori centrati intorno al valore medio di una variabile target. Il risultato sono dati circondati solo da una deviazione standard unitaria, cioè la media della colonna viene posta a zero, mentre la deviazione standard diventa 1. I nuovi valori standardizzati si calcolano come:
X^'=(X-μ)/σ
- Normalizzazione: Un’altra tecnica di scaling dei dati è la normalizzazione, questa usa una formula per spostare i valori in un intervallo compreso tra 0 e 1. Questa tecnica risulta particolarmente utile quando si vogliono applicare algoritmi di apprendimento basati sulla distanza dal momento che questi lavorano perfettamente su intervalli piccoli e predefiniti. I valori normalizzati si calcolano come:
X^'=(X-X_min)/(X_max-X_min )
Dove X_max e X_min sono i valori massimi e minimi osservati.
In ogni progetto o problema reale i dati catturati sono grezzi, per cui anche il training set e il test set non sono disponibili da subito separatamente. Per avere analisi più accurate, proviamo a combinare i dati di training e di test e ad analizzarli insieme. Pre-elaborare tutti i dati insieme permetterà di costruire modelli più accurati che si adattano meglio ai dati. Una volta terminato il preprocessing dell’intero dataset, possiamo separare nuovamente training e test set. Avviamo il processo di elaborazione e feature engineering sul nostro dataset.
# Separiamo la variabile target dagli altri attributi
var_target = housing_train_data['SalePrice']
housing_test_id = housing_test_data['Id']
housing_test_data = housing_test_data.drop(['Id'],axis = 1)
housing_data2 = housing_train_data.drop(['SalePrice'], axis = 1)
# Concateniamo training e test set
housing_train_test = pd.concat([housing_data2,housing_test_data], axis=0, sort=False)
# Cerchiamo i valori NaN e grafichiamoli
nan_df = pd.DataFrame(housing_train_test.isna().sum(), columns = ['Sum_NaN'])
nan_df['feature_set'] = nan_df.index
nan_df['amount_percent'] = (nan_df['Sum_NaN']/1460)*100
plt.figure(figsize = (32,8))
sns.barplot(x = nan_df['feature_set'], y = nan_df['amount_percent'])
plt.xticks(rotation=45)
plt.title('Features and their corresponding NaN Weightage')
plt.xlabel('Features Sets')
plt.ylabel('Amount of Missing Data')
plt.show()
>>>
.png.aspx)
# Nonostante il numero di NaN sembri essere elevato, ciò non vuol dire che siano tutti valori mancanti. Infatti, leggendo le descrizioni delle colonne ci aspettiamo che possano esserci alcuni valori mancanti che quindi non sono NaN. Andremo a riempire questi valori in maniera appropriata.
# Convertiamo in stringhe le variabili non numeriche memorizzate come interi
housing_train_test['MSSubClass'] = housing_train_test['MSSubClass'].apply(str)
housing_train_test['YrSold'] = housing_train_test['YrSold'].apply(str)
housing_train_test['MoSold'] = housing_train_test['MoSold'].apply(str)
# Ora, riempiamo manualmente i valori categorici nulli
housing_train_test['Functional'] = housing_train_test['Functional'].fillna('Typ')
housing_train_test['Electrical'] = housing_train_test['Electrical'].fillna("SBrkr")
housing_train_test['KitchenQual'] = housing_train_test['KitchenQual'].fillna("TA")
housing_train_test["PoolQC"] = housing_train_test["PoolQC"].fillna("None")
housing_train_test["Alley"] = housing_train_test["Alley"].fillna("None")
housing_train_test['FireplaceQu'] = housing_train_test['FireplaceQu'].fillna("None")
housing_train_test['Fence'] = housing_train_test['Fence'].fillna("None")
housing_train_test['MiscFeature'] = housing_train_test['MiscFeature'].fillna("None")
# Per alcune colonne andiamo invece a riempire con la moda
housing_train_test['Exterior1st'] = housing_train_test['Exterior1st'].fillna(housing_train_test['Exterior1st'].mode()[0])
housing_train_test['Exterior2nd'] = housing_train_test['Exterior2nd'].fillna(housing_train_test['Exterior2nd'].mode()[0])
housing_train_test['SaleType'] = housing_train_test['SaleType'].fillna(housing_train_test['SaleType'].mode()[0])
# Rimuoviamo gli attributi che non sembrano influire sui prezzi
non_affecting_cols = ['GarageYrBlt','YearRemodAdd']
housing_train_test = housing_train_test.drop(non_affecting_cols, axis = 1)
# Andiamo ora ad applicare la Feature Engingeering. Andiamo a creare dei nuovi attributi combinando quelli esistenti. Questo ci aiuterà ad aumentare le performance del modello.
# Combiniamo degli attributi per crearne di nuovi
housing_train_test["SqFtPerRoom"] = housing_train_test["GrLivArea"] / (housing_train_test["TotRmsAbvGrd"] + housing_train_test["FullBath"] + housing_train_test["HalfBath"] + housing_train_test["KitchenAbvGr"])
housing_train_test['Total_Home_Quality'] = housing_train_test['OverallQual'] + housing_train_test['OverallCond']
housing_train_test['Total_Bathrooms'] = (housing_train_test['FullBath'] + (0.5 * housing_train_test['HalfBath']) + housing_train_test['BsmtFullBath'] + (0.5 * housing_train_test['BsmtHalfBath']))
housing_train_test["HighQualSF"] = housing_train_test["1stFlrSF"] + housing_train_test["2ndFlrSF"]
# Creiamo una colonna di variabili dummy
housing_train_test_dummy = pd.get_dummies(housing_train_test)
Concludiamo così la fase di Feature Engineering sul dataset. In seguito, addestreremo dei modelli di machine learning per effettuare le predizioni.
Costruire modelli predittivi di Machine Learning
Il Machine Learning è il ramo dell’intelligenza artificiale che dipende maggiormente dall’analisi dei dati. Esso si basa sull’idea che i sistemi e gli algoritmi apprendono dalle caratteristiche e dagli schemi dei dati su cui sono addestrati. L’addestramento rende gli algoritmi in grado di prendere decisioni senza o con il minimo intervento umano. Il machine learning si è evoluto col tempo dal semplice pattern recognition e si basa sulla teoria che i programmi possono apprendere se vengono addestrati, senza bisogno di specifiche dichiarazioni sui risultati. Il volume crescente dei dati che si osservano ogni giorno ha elevato l’interesse per il machine learning. È quindi importante che questo tipo di computazioni venga reso più economico e che soprattutto venga eseguito sul Cloud.
Iniziamo a implementare algoritmi di Machine Learning sul nostro dataset.
# Prepariamo il training e il test set
housing_train_data = housing_train_test_dummy[0:2930]
housing_test_data = housing_train_test_dummy[2930:]
housing_test_data['Id'] = housing_test_id
housing_train_data.shape
>>> (2919, 326)
# Importiamo le librerie per costruire i modelli di Machine Learning
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, BayesianRidge
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.metrics import accuracy_score
# Prendiamo il logaritmo naturale elemento per elemento per standardizzare il vettore house_train
housing_sample = housing_train_data[0:1460]
target_log = np.log1p(var_target)
target_log.shape
>>> (1460,)
housing_sample.shape
>>> (1460, 326)
housing_sample.fillna(housing_sample.mean(), inplace=True)
# Splittiamo i dati per separare le feature dalle etichette
X_train,X_val,y_train,y_val = train_test_split(housing_sample,target_log,test_size = 0.1,random_state=42)
# Vogliamo usare più algoritmi di Machine Learning per fittare i dati. Si raccomanda sempre di usare più di un algoritmo per confrontare i risultati e scegliere quello che si adatta meglio.
# 1. Regressione Lineare
linear_regression = LinearRegression()
linear_regression.fit(X_train, y_train)
linear_regression_score = linear_regression.score(X_train, y_train)
# 2. Regressore SVM
support_vector_regressor = SVR()
support_vector_regressor.fit(X_train, y_train)
support_vector_score = linear_regression.score(X_train, y_train)
# 3. Regressore Decision Tree
decision_tree_regressor = DecisionTreeRegressor()
decision_tree_regressor.fit(X_train, y_train)
decision_tree_score = linear_regression.score(X_train, y_train)
# 4. Regressore Random Forest
random_forest_regressor = RandomForestRegressor(n_estimators=150)
random_forest_regressor.fit(X_train, y_train)
random_forest_score = random_forest_regressor.score(X_train, y_train)
# 5. Regressore Bayesiano
bayesian_ridge_regressor = BayesianRidge(compute_score=True)
bayesian_ridge_regressor.fit(X_train, y_train)
bayesian_ridge_score = bayesian_ridge_regressor.score(X_train, y_train)
# 6. Gradient Boost
gradient_boost_regressor = GradientBoostingRegressor()
gradient_boost_regressor.fit(X_train, y_train)
gradient_boost_score = bayesian_ridge_regressor.score(X_train, y_train)
# Confrontiamo i singoli valori di accuracy
accuracy_scores = []
Used_ML_Models = ['Linear Regression','Support Vector Machines','Decision Trees',
'Random Forest Regression','Bayesian Ridge Regression',
'Gradient Boost Regression']
accuracy_scores.append(linear_regression_score)
accuracy_scores.append(support_vector_score)
accuracy_scores.append(decision_tree_score)
accuracy_scores.append(random_forest_score)
accuracy_scores.append(bayesian_ridge_score)
accuracy_scores.append(gradient_boost_score)
score_comparisons = pd.DataFrame(Used_ML_Models, columns = ['Regressors'])
score_comparisons['Accuracy on Training Data'] = accuracy_scores
score_comparisons
>>>
Regressors Accuracy on Training Data
0 Linear Regression 0.946865
1 Support Vector Machines 0.946865
2 Decision Trees 0.946865
3 Random Forest Regression 0.982092
4 Bayesian Ridge Regression 0.926543
5 Gradient Boost Regression 0.939485
# Come possiamo osservare, la maggior parte delle predizioni rientra nello stesso intervallo, ma il regressore Random Forest presenta il miglior valore di accuracy sul training set.
# Calcoliamo gli score di predizione finali sul test set
final_prediction = random_forest_regressor.predict(X_val)
rfc_score = random_forest_regressor.score(X_train, y_train)
rfc_score
>>> 0.9818293405075341
# Ordiniamo e visualizziamo graficamente le features secondo la loro importanza nel processo di regressione
important_features = random_forest_regressor.feature_importances_
plt.figure(figsize = (15,5))
plt.barh(housing_sample.columns[:15], important_features[:15])
>>>
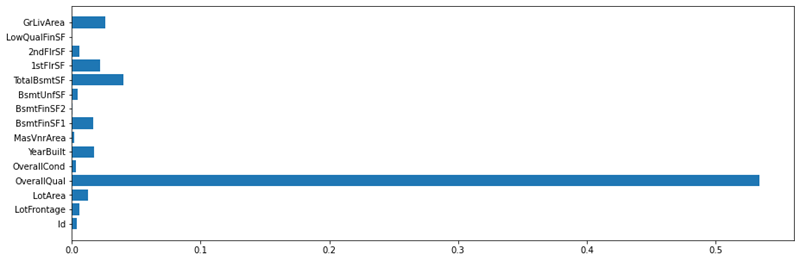
# Ora che conosciamo quali attributi hanno maggior importanza nelle predizioni, possiamo eseguire alcune predizioni sul test set per prevedere il prezzo di vendita di alcune case, dato il loro Id.
housing_sample = housing_train_data[0:1459]
housing_sample.fillna(housing_sample.mean(), inplace=True)
Pred_test = random_forest_regressor.predict(housing_sample)
Sale_price_pred = pd.DataFrame(housing_test_id, columns = ['Id'])
Pred_test = np.expm1(Pred_test)
Sale_price_pred ['SalePrice'] = Pred_test
Sale_price_pred.head()
>>>
Id SalePrice
0 1461 205511.779437
1 1462 176017.744645
2 1463 223587.840662
3 1464 156579.649258
4 1465 263174.543961
# Con questo concludiamo la nostra analisi.
L’obiettivo di questo progetto è stato capire quali sono i fattori maggiormente determinanti nel decidere l’acquisto di un immobile in Iowa. Abbiamo eseguito un modello predittivo sui dati di test e predetto i prezzi di alcune case. Dalle nostre analisi e dal modello costruito possiamo dedurre le seguenti conclusioni:
- per ottenere predizioni di successo sui prezzi degli immobili possiamo usare un modello Random Forest di regressione;
- abbiamo, infatti, osservato che il regressore Random Forest offre prestazioni megliori degli altri modelli di ML testati sul dataset;
- per quanto riguarda l’importanza delle features, abbiamo osservato che l’attributo Overall Quality è il fattore più importante nel determinare il prezzo, seguito dagli attributi Living Area e High Quality Surface Built.
Conclusioni sul Machine Learning e prossimi passi
Il Machine Learning si basa sul concetto che i sistemi possono imparare a effettuare predizioni a partire dal processo di addestramento sui dati forniti in input. Tali predizioni valgono anche per dati che i modelli non hanno mai visto prima, il che rende questi algoritmi intelligenti. In questo progetto abbiamo dimostrato l’utilità di costruire algoritmi intelligenti per risolvere problemi comuni, concetto che avevamo introdotto già nel primo capitolo. Ricordiamo che il Machine Learning è un elemento fondamentale per implementare l’Intelligenza Artificiale (IA) nel mondo reale, infatti, la maggior parte degli algoritmi di IA usati oggi hanno motori basati sul ML e questo progetto è un buon punto di partenza nel nostro viaggio attraverso il mondo dell’apprendimento automatico.
Nei prossimi capitoli esamineremo altri aspetti dell’Intelligenza Artificiale utili a lavorare su tipi diversi di dati. Esploreremo prima la programmazione logica in Python per costruire applicazioni di IA, in seguito lavoreremo su dati sotto forma di Linguaggio Naturale, Immagini e Suoni. Questi concetti rientrano nell’ambito dell’intelligenza artificiale intuitiva e cognitiva.
A seguire:
- Programmazione Logica in Python;
- Lavorare col linguaggio naturale scritto e parlato;
- Apprendere dati voice-based.