Introduzione
Il Natural Language Processing (NLP) è una complessa suite di tecniche e algoritmi di Intelligenza Artificiale (IA) per il trattamento del linguaggio naturale ampiamente integrata in moltissimi progetti reali di molte aziende.
Lo NLP è anche un’applicazione dell’intelligenza artificiale che lavora con l’analisi e la costruzione di sistemi intelligenti le cui funzionalità si basano sul linguaggio umano, ad esempio, l’inglese. Processare il linguaggio naturale è utile per quei sistemi che devono interagire direttamente con gli utenti tramite testo o linguaggio parlato, dal momento che gli utenti forniscono gli input direttamente sotto forma di linguaggio ad esempio usando la lingua inglese o italiana.
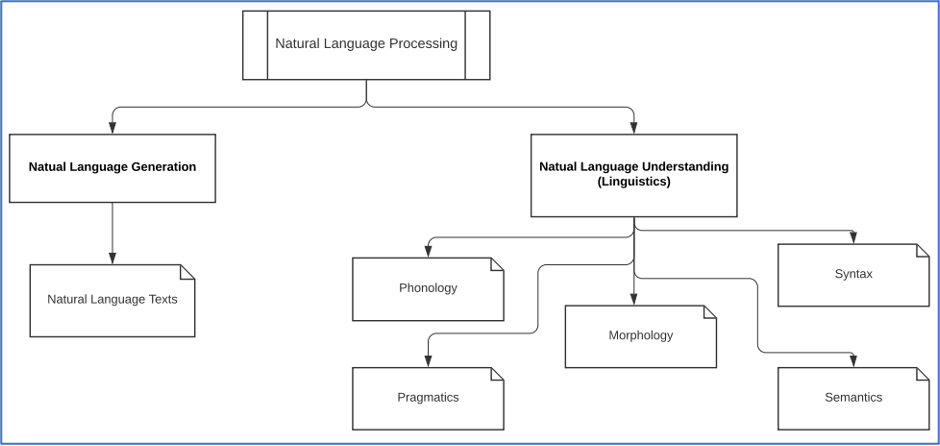
Natural Language Understanding (NLU): la fase di understanding è la parte dell’elaborazione del linguaggio che associa l’input espresso in linguaggio naturale a una rappresentazione utilizzabile dal sistema. Durante la fase di NLU è anche possibile analizzare diversi aspetti del linguaggio in input.
Natural Language Generation (NLG): la fase di generazione consiste nel processo di generare linguaggio naturale a partire dall’output della fase di NLU. Generalmente, la fase di NLG parte dalla pianificazione del testo, o Text Planning, che consiste nell’estrazione di contenuti rilevanti da una base di conoscenza. In seguito, avviene la pianificazione della frase, o Sentence Planning, in cui vengono selezionate le parole che costituiranno la frase da produrre. Infine, si ha la realizzazione del testo vera e propria, o Text Realization, che consiste nel creare la struttura finale della frase.
Sfide del Natural Language Processing
- Ambiguità del lessico: si tratta di un primo livello di ambiguità che si verifica per le singole parole. Ad esempio, data la parola “board” da sola, non sappiamo se ci riferiamo a un sostantivo o a un verbo. Questo può causare ambiguità nell’elaborazione del testo.
- Ambiguità a livello sintattico: un altro tipo di ambiguità è quella relativa al modo in cui una frase deve essere percepita rispetto a come questa viene interpretata dalla macchina.
- Referential Ambiguity: anche l’uso dei pronomi costituisce un’ambiguità, detta referential ambiguity. Ad esempio: due ragazze stanno correndo quando lei dice di essere esausta. In questo caso, non è possibile interpretare correttamente chi delle due sia stanca.
Scienza e Terminologia dietro la cognizione umana
L’elaborazione del linguaggio è una branca dell’IA nuova e in rapida crescita. Esistono alcuni termini tecnici che si riferiscono nello specifico proprio all’elaborazione del linguaggio che possono aiutarci a capire meglio l’NLP.
- Fonologia: il sistema di organizzazione dei suoni del linguaggio.
- Morfologia: la costruzione di parole nuove a partire da un insieme di unità primitive dette Morfemi.
- Semantica: come nei linguaggi di programmazione, la semantica riguarda la costruzione di frasi significative attraverso l’uso delle parole a disposizione.
- Sintassi: in generale, è il modo di sistemare le parole all’interno di una frase. Inoltre, la sintassi serve a determinare il ruolo delle parole all’interno della struttura della frase.
- World Knowledge: gli algoritmi di NLP necessitano di una conoscenza estesa generale del contesto per costruire frasi significative.
- Pragmatica: situazioni diverse potrebbero richiedere aggiustamenti particolari delle frasi e la pragmatica è la parte che si occupa della costruzione delle frasi per scenari tipici.
- Discorso: si occupa del mettere in sequenza la frase. In particolare, il discorso cerca di capire come la formazione di una frase possa influenzare la frase successiva.
Nella costruzione di un elaboratore di linguaggio naturale abbiamo in totale cinque passaggi esecutivi:
- Analisi lessicale: l’elaborazione del linguaggio naturale mediante algoritmi di NLP comincia con l’identificazione e l’analisi strutturale delle parole in input. Questa parte è detta analisi del lessico, dove per lessico si intende un vocabolario delle parole e delle frasi del linguaggio. L’analisi lessicale consiste nel dividere le parole in paragrafi e poi in frasi.
- Analisi sintattica / Parsing: una volta formata la struttura della frase, si effettua l’analisi sintattica per verificare la correttezza grammaticale delle frasi. Questa serve anche a instaurare relazioni tra parole e eventualmente eliminare frasi prive di senso logico. Ad esempio, un parser di lingua inglese rifiuterebbe la frase “an umbrella opens a man”.
- Analisi semantica: nel processo di analisi semantica si verifica il significato del testo, ad esempio, si definisce un dizionario completo di tutte le parole del testo per poi verificare la significatività delle frasi e delle singole parole. Ad esempio, un parser semantico rifiuterebbe una frase del tipo “ghiaccio caldo”.
- Integrazione del discorso: il processo di integrazione del discorso si occupa dell’ordinare le frasi in ordine in modo da formare un testo, in modo che ogni frase sia in relazione con la precedente e la successiva. Il compito del componente di integrazione del discorso è appunto la verifica di queste relazioni.
- Analisi pragmatica: completate tutte le verifiche grammaticali e sintattiche, le frasi vengono infine controllate per verificarne la loro rilevanza pratica. In particolare, durante l’analisi pragmatica, si revisionano e si valutano ancora una volta tutte le frasi per verificare la loro applicabilità nel mondo reale, usando una conoscenza generale.
Introduzione a NLTK
Il contesto è il requisito fondamentale affinché un linguaggio funzioni correttamente. Così è anche per noi umani, infatti, se non conosciamo il contesto di riferimento di una conversazione, non siamo in grado di parteciparvi. Per dotare le macchine di contesto, possiamo far uso del Natural Language Processing Toolkit di Python, NLTK. In un certo senso, questo consente alle macchine di capire il contesto della conversazione come fanno gli esseri umani. Vediamo alcune nozioni base di NLTK.
# Installiamo il pacchetto NLTK
pip install nltk
>>> Note: you may need to restart the kernel to use updated packages.
import nltk
# Gensim è un pacchetto python per la modellazione semantica
pip install gensim
# Pattern è un’altra di supporto a gensim
pip install pattern
# NLTK dispone di una vasta quantità di dati utilizzabili per l’elaborazione del linguaggio naturale. Scarichiamo tutti questi dati per poter usare quelli che ci servono in questa sessione.
nltk.download()
>>> showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
>>> True
>>>
.png.aspx;)
# Durante il download, selezioniamo “all corpora” per scaricare tutti i dati. Una volta completato il download apparirà sul notebook la scritta True
Proseguiamo analizzando tre concetti fondamentali del NLP: Tokenizzazione, Stemming e Lemmatizzazione.
Tokenizzazione, Stemming e Lemmatizzazione
Tokenizzazione
La tokenizzazione è il processo di spezzare le frasi in singole unità dette token. I token possono essere parole, numeri o simboli di punteggiatura. La tokenizzazione si può anche chiamare “word segmentation”. Vediamo un esempio di tokenizzazione:
- Input: Cricket, Baseball and Hockey are primarly hand-based sports.
- Output tokenizzato: “Cricket”, “,”, “Baseball”, “and”, “Hockey”, “are”, “primarily”, “hand”, “based”, “sports”, ”.”
L’inizio e la fine della frase sono detti boundaries e talvolta la tokenizzazione serve proprio a identificare i boundaries delle frasi.
A seguire alcuni pacchetti utili.
- Sent_tokenize Package: è un pacchetto per la tokenizzazione delle frasi che converte il testo in input in frasi. Si può installare eseguendo il seguente comando su Jupyter Notebook:
from nltk.tokenize import sent_tokenize
- Word_tokenize Package: opera in maniera simile alla tokenizzazione in frasi ma serve a dividere il testo in input in parole. Può essere installato su Jupyter col comando:
from nltk.tokenize import word_tokenize
- WordPunctTokenizer Package: a differenza del word tokenizer, questo tokenizer usa come separatori sia gli spazi bianchi che i segni di punteggiatura. Si può importare con:
from nltk.tokenize import wordpunct_tokenize
Stemming
Nello studio del linguaggio naturale usato nelle conversazioni si possono trovare diverse "variazioni" per motivi grammaticali. Ad esempio, parole come virtuale, virtualità e virtualizzazione hanno lo stesso significato di base ma hanno significati diversi in base alla frase in cui si trovano. Affinchè gli algoritmi di nltk funzionino correttamente, bisogna che comprendano queste variazioni. Lo stemming è appunto il processo euristico che cerca di capire la radice delle parole per analizzarne meglio il significato.
Altri pacchetti utili sono riportati a seguire.
- PorterStemmer package: è una libreria Python che fa uso dell’algoritmo di Porter per calcolare gli stem. Per comprenderne il funzionamento, consideriamo ad esempio la parola “running”, per la quale l’operazione di stemming produce la parola “run”. La libreria si può installare col comando:
from nltk.stem.porter import PorterStemmer
- LancasterStemmer package: il funzionamento dello stemmer lancaster è simile all’algoritmo di Porter ma ha un livello più basso di precisione, infatti rimuove solo la desinenza verbale dalla parola. Ad esempio, l’algoritmo di Lancaster per la parola “writing” ritorna “writ”. Si può importare col comando:
from nltk.stem.lancaster import LancasterStemmer
- SnowballStemmer package: ha lo stesso funzionamento dei precedenti e può essere importato eseguendo:
from nltk.stem.snowball import SnowballStemmer.
Questi algoritmi in generale sono intercambiabili nonostante varino in precisione.
Lemmatizzazione
Aggiungere dettagli morfologici alle parole di certo aiuta nell’estrazione delle rispettive forme di base e questo processo può essere effettuato semplicemente con la lemmatizzazione, che effettua sia un’analisi verbale che morfologica delle parole. Lo scopo di questa operazione è di rimuovere le terminazioni delle parole in maniera flessibile. La forma base risultante dalla lemmatizzazione è detta “lemma”.
WordNetLemmatizer package è un pacchetto che estrae i lemmi delle parole in base alla funzione della parola, ad esempio se nella frase questa ha la funzionalità di nome o di pronome. La libreria si può importare eseguendo: from nltk.stem import WordNetLemmatizer
Chunking dei dati
Il Chunking, come suggerisce il termine inglese, consiste nel suddividere i dati in più parti, dette chunks. Questo processo è importante nel regno del Natural Language Processing. La funzione principale del chunking è di classificare diverse parti del discorso e frasi brevi come frasi nominali. Completata la fase di tokenizzazione, l’input è stato diviso in token, a questo punto il chunking può essere usato per etichettare i token in modo da migliorare la comprensione dell’algoritmo. Esistono due metodologie di chunking:
- Chunking Up: il chunking verso l’alto guarda il problema da lontano. Durante la fase di suddivisione, le frasi vengono astratte e le singole parole generalizzate. Ad esempio, una domanda del tipo “A cosa serve un autobus?” il chunking risponde con “Trasporto”.
- Chunking Down: al contrario, il chunking verso il basso serve ad andare più in profondità e a vedere gli oggetti in maniera più specifica, ad esempio, la domanda “Cos’è un auto?” può produrre dettagli specifici come il colore, la forma, il brand o le dimensioni dell’auto.
# Effettuiamo il chunking per frasi nominali, che è un tipo particolare di chunking. Andiamo a definire le nozioni grammaticali che il programma userà per effettuare il chunking.
import nltk
# Definiamo la struttura delle frasi
# DT -> Determinant, VBP ->Verb, JJ -> Adjective, IN -> Preposition and NN -> Noun
test_phrases = [("an","DT"), ("astonishing","JJ"), ("leopard","NN"), ("is","VBP"), ("running","VBP"), ("around", "IN"), ("the","DT"),("ground","NN")]
# Il chuncking ci permette di definire la grammatica come un’espressione regolare
def_grammar = "NP:{<DT>?<JJ>*<NN>}"
parse_chunk_tests = nltk.RegexpParser(def_grammar)
parse_chunk_tests.parse(test_phrases)
>>> This is the categorical output >>> Tree('S', [Tree('NP', [('an', 'DT'), ('astonishing', 'JJ'), ('leopard', 'NN')]), ('is', 'VBP'), ('running', 'VBP'), ('around', 'IN'), Tree('NP', [('the', 'DT'), ('ground', 'NN')])])
final_chunk_output = parse_chunk_tests.parse(test_phrases)
final_chunk_output.draw()
>>>

# Possiamo vedere che il chunking ha suddiviso l’input in frasi distinte in base alla differenziazione grammaticale fornita.
Nell’ultima parte di questo capitolo implementeremo un algoritmo di NLP per esaminare un sito web in forma testuale e il modello ci dirà di cosa tratta l’articolo. Questo tipo di classificazione è detta topic modelling e viene usata per identificare pattern all’interno dei dati.
Topic Modelling e Identificazione di pattern nei dati
Quasi sempre i documenti e le discussioni ruotano intorno a un particolare argomento. Alla base di ogni conversazione c’è un argomento e la discussione ruota intorno a questo. Affinché un algoritmo di NLP capisca e operi sulla conversazione umana, deve comprendere l’argomento di discussione di cui si sta parlando, e per determinarlo gli algoritmi eseguono tecniche di pattern matching. Questo particolare processo è chiamato topic modelling e viene tipicamente adoperato per trovare gli argomenti nascosti all’interno dei documenti che bisogna elaborare. Il topic modelling viene usato in due scenari principali.
- Classificazione del Testo: può infatti migliorare la classificazione di dati testuali dato che la modellazione raggruppa insieme le parole, i sostantivi e i verbi simili e non usa le singole parole.
- Sistemi di Recommendation: i sistemi di recommendation si basano sulla ricerca di contenuti simili, per cui gli algoritmi di topic modelling si possono usare per calcolare meglio le matrici di similarità dei dati forniti.
# Applichiamo l’NLP per leggere una pagina web e classificare l’argomento della pagina
# Installiamo il pacchetto nltk
pip install nltk
import nltk
nltk.download()
# Prendiamo un link di una pagina e usiamo il modulo urllib per prelevare il contenuto dalla pagina
import urllib.request
test_resp = urllib.request.urlopen('https://en.wikipedia.org/wiki/Mercedes-Benz')
input_page = test_resp.read()
print(input_page)
>>>
# Questa è una lettura statica della pagina elaborata durante il crawling.
# Andiamo a lavorare con la libreria Python Beautiful Soup che ci aiuterà a ripulire il testo estraendolo da pagine HTML o XML
from bs4 import BeautifulSoup
soup_type = BeautifulSoup(input_page,'html5lib')
input_text = soup_type.get_text(strip = True)
print(input_text)
>>>

# Vediamo che l’output generato da BeautifulSoup è più pulito
# Abbiamo quindi dei gruppi puliti di dati. Il prossimo step è convertire questi gruppi in token che possono essere usati dagli algoritmi di NLP
build_tokens = [token for token in input_text.split()]
print(build_tokens)
>>>

# Questo output consiste nella tokenizzazione delle parole
# Ora andiamo a contare la frequenza delle parole
# La funzione FreqDist() di NLTK è adatta a questo scopo. Andremo a pre-elaborare i dati rimuovendo parole come at, the, a e for perché non influiranno sul risultato.
from nltk.corpus import stopwords
in_request = stopwords.words('english')
clean_text = build_tokens[:]
for token in build_tokens:
if token in stopwords.words('english'):
clean_text.remove(token)
freq_dist = nltk.FreqDist(clean_text)
for k,v in freq_dist.items():
print(str(k) + ':' + str(v))
# Infine, plottiamo i risultati ottenuti in un grafico per visualizzare quali sono gli argomenti più discussi all’interno della pagina
freq_dist.plot(20, cumulative=False)
>>>
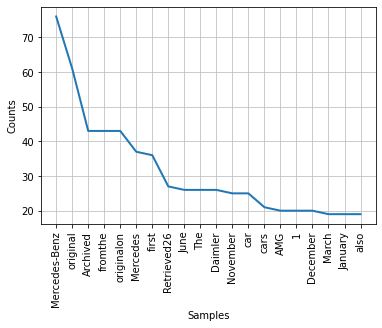
# L’output mostra chiaramente che “Mercedes-Benz” è l’argomento chiave di discussione attraverso la nostra pagina web.
In questo capitolo abbiamo svolto una breve analisi del linguaggio naturale e nei prossimi capitoli esploreremo più a fondo concetti più complessi. L’esempio visto ci ha permesso di predire quale fosse il contenuto di una pagina web, ma esistono moltissimi altri casi d’uso in cui l’NLP risulta utile.
Prossimamente
Col Natural Language Processing abbiamo fatto un altro passo avanti nello studio dell’Intelligenza Artificiale. Il NLP è un argomento molto vasto e importante nell’imitazione del ragionamento umano dal momento che il linguaggio gioca un ruolo cruciale in molti dei nostri processi. Dall’elaborazione del linguaggio naturale dipende una vasta quantità di casi d’uso diffusi in molti domini applicativi.
Nei prossimi capitoli approfondiremo l’utilizzo pratico del NLP all’interno del mercato attuale e la sua influenza sull’Intelligenza Artificiale.
Prossimi argomenti trattati:
- Problema del Bag of Word (BOW);
- Riconoscimento del parlato;
- Analisi del Sentiment tramite il linguaggio.