l’Intelligenza Artificiale e Python
Nel capitolo precedente abbiamo visto come l’Intelligenza Artificiale si stia evolvendo nel mondo odierno e come i programmatori stiano costruendo macchine sempre più intelligenti. Abbiamo anche compreso l’importanza di unire codice e statistica, in modo da raggiungere questo obiettivo. Questo capitolo verte sui diversi tipi di dati che potremo utilizzare programmando in Python e le rispettive variabili che potrebbero memorizzare tali dati. Verso la fine cercheremo anche di creare, tramite l’impiego di librerie Python, dei costrutti che siano di supporto alla raccolta e alla manipolazione di dati numerici.
Programmazione Python orientata agli oggetti
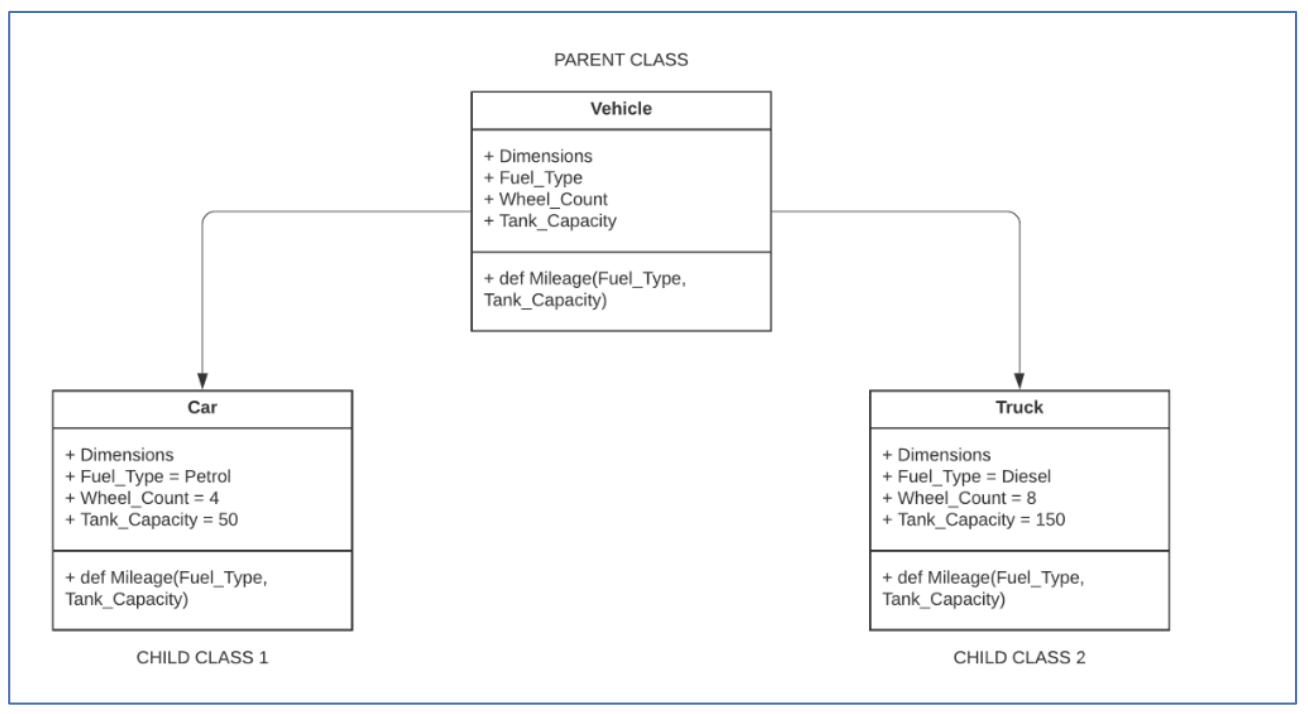
La programmazione orientata agli oggetti, anche detta OOP, è un paradigma di programmazione per la creazione di codice modulare che ruota intorno ai concetti di “classe” e “oggetto”. Alcuni importanti termini associati alla OOP sono i seguenti:
- classi: sono componenti che spesso espongono una serie di funzioni e attributi associati a un nome e che rappresentano una sorta di contenitore astratto;
- attributi: generalmente, si tratta dei dati associati a ogni classe. Un esempio sono le variabili dichiarate durante la creazione della classe;
- oggetti: un oggetto è un’istanza di una classe. Possono esserci più oggetti per una classe e ogni singolo oggetto espone le proprietà della classe.
Rappresentazione della OOP
Creare classi e oggetti in Python
Le classi in Python vengono create usando la parola chiave class. La definizione della classe e delle sue proprietà avviene all’interno di un blocco di codice indentato. La definizione di una classe può contenere diverse funzioni e variabili.
# Creiamo una classe Math con 2 funzioni
class Math:
def subtract (self, i, j):
return i–j
def add (self, x, y):
return x+y
# Creiamo una classe Persona con 2 attributi e 1 funzione
class Person:
name = “Kevin”
def __init__ (self):
self.age = 34
# Creiamo un oggetto Persona e stampiamo i suoi attributi
p1 = Person()
print (p1.name)
>>> Kevin
print (p1.age)
>>> 34
Costruttori ed Ereditarietà
Il costruttore è una funzione di inizializzazione che viene sempre chiamata quando si crea un’istanza di classe. Il costruttore in Python è chiamato __init__() e definisce le specifiche di una classe e i suoi attributi.
L’ereditarietà di classe è una azione legata al concetto “utilizzare le proprietà di una classe originaria” per “assegnare queste stesse proprietà a una classe figlio”. Ciò crea delle relazioni del tipo “La classe A è una classe B”, ad esempio un triangolo (classe child) è una forma (classe parent). Tutte le funzioni e gli attributi della superclasse sono ereditati dalla sottoclasse.
- Overriding: durante l’ereditarietà, il comportamento della classe figlio o della sottoclasse può essere modificato. Fare modifiche del genere sulle funzioni significa “sovrascrivere” la classe e tale sovrascrittura può essere ottenuta dichiarando funzioni nella sottoclasse aventi lo stesso nome delle funzioni della superclasse. Le funzioni sovrascritte all’interno della sottoclasse hanno la priorità su quelle nella classe parent;
- Composizione: le classi possono anche essere costituite da classi più piccole che supportano relazioni del tipo “la classe A ha una classe B”, come ad esempio un Dipartimento “ha” gli Studenti;
- Polimorfismo: le funzionalità di funzioni apparentemente simili tra loro possono cambiare durante l’esecuzione. Questo aspetto è detto Polimorfismo, e implica che due oggetti di classi parent diverse abbiano lo stesso insieme di funzioni. L’aspetto esteriore di tali funzioni è lo stesso, ma le loro implementazioni sono diverse.
# Creiamo una classe e istanziamo le variabili
class Animal_Dog:
species = "Canis"
def __init__(self, name, age):
self.name = name
self.age = age
# Metodo di istanza
def description(self):
return f"{self.name} is {self.age} years old"
# Altro metodo di istanza
def animal_sound(self, sound):
return f"{self.name} says {sound}"
# Verifica il tipo dell’oggetto
Animal_Dog()
>>> <__main__.Animal_Dog object at 0x106702d30>
# Nonostante a e b siano entrambe istanze della classe Dog, rappresentano due oggetti distinti in memoria.
a = Animal_Dog()
b = Animal_Dog()
a == b
>>> False
# Istanziamo degli oggetti con gli argomenti del costruttore di classe
fog = Animal_Dog("Fog", 6)
bunny = Animal_Dog("Bunny", 7)
print (bunny.name)
>>> 'Bunny'
Print (bunny.age)
>>> 7
# Accesso diretto agli attributi
print (bunny.species)
>>> 'Canis'
# Creiamo un nuovo oggetto a cui accedere tramite le funzioni di un’istanza
fog = Dog("Fog", 6)
fog.description()
>>> 'Fog is 6 years old'
fog.speak("Whoof Whoof")
>>> 'Fog says Whoof Whoof'
fog.speak("Bhoof Whoof")
>>> 'Fog says Bhoof Whoof '
# Esempio di ereditarietà di classe
class GoldRet(Dog):
def speak(self, sound="Warf"):
return f"{self.name} says {sound}"
bunny = GoldRet("Bunny", 5)
bunny.speak()
>>> 'Bunny says Warf'
bunny.speak("Grrr Grrr")
>>> 'Bunny says Grrr Grrr'
Variabili e tipi di dati in Python
Le variabili sono locazioni di memoria riservate che memorizzano i valori su esse definite. Quando è creata una variabile viene ad essa assegnata una porzione di memoria. L’interprete alloca blocchi di memoria a seconda della tipologia relativa alla variabile dichiarata. Pertanto, in base al tipo di assegnamento della variabile ovvero intero, float, stringa o altro, sono assegnate porzioni di memoria di diverse dimensioni.
- Dichiarazione: Le variabili in Python non hanno bisogno di essere dichiarate esplicitamente per riservare a esse spazio in memoria. L’assegnazione della memoria avviene, infatti, automaticamente quando è assegnato un valore alla variabile. Per assegnare valori alle variabili si adopera il simbolo
=.
- Assegnamento multiplo: Python consente di assegnare un singolo valore a più variabili e questa dichiarazione può essere fatta per tutte le variabili nello stesso momento.
- Rimozione dei riferimenti: una volta creati, i riferimenti di memoria possono anche essere eliminati. Per eliminare il riferimento a un oggetto viene usata l’istruzione
del. Questa istruzione supporta anche l’eliminazione di oggetti multipli.
- Stringhe: le stringhe sono insiemi di caratteri, per le quali Python ammette la dichiarazione attraverso le virgolette sia singole che doppie. Sottoinsiemi di una stringa possono essere ottenuti usando gli operatori “slice” (
[ ] e [:]), per i quali l’indicizzazione parte da 0 a sinistra e -1 a destra della stringa. Il segno + viene invece usato come operatore per concatenare più stringhe, mentre il segno * viene usato per ripetere una stringa più volte.
Conversione dei tipi di dato
| Funzione |
Descrizione |
int(x [,base])
|
converte un dato input in un intero. La base di default è 10 |
long(x [,base])
|
converte un dato input in un long |
float(x)
|
converte l’input in un numero a virgola mobile |
complex(real [,imag])
|
viene usato per creare numeri complessi |
str(x)
|
converte un qualunque oggetto in una stringa |
eval(str)
|
data una stringa, ritorna un oggetto |
tuple(s)
|
converte in una tupla |
list(s)
|
converte in una lista |
set(s)
|
crea un insieme a partire da s (rimuovendo i duplicati) |
unichr(x)
|
converte un intero in un carattere con codifica Unicode |
Uno sguardo alle variabili e ai tipi
I dati memorizzati come variabili in Python vengono astratti come oggetti. I dati possono essere rappresentati da oggetti oppure attraverso relazioni tra singoli oggetti. Quindi, ogni variabile con i suoi valori è un oggetto di una classe che dipende dal tipo di dato memorizzato.
Int_var = 100 # Variabile intera
Float_var = 1000.0 # Variabile float
String_var = "John" # Variabile stringa
print (int_var)
>>> 100
print (float_var)
>>> 1000.0
Print (string_var)
>>> John
# Assegnamento multiplo: tutte le variabili vengono assegnate alla stessa locazione di memoria
a = b = c = 1
# Assegnare più variabili a più valori
a,b,c = 1,2,"jacob"
# Assegnare variabili e eliminare i riferimenti
var1 = 1
var2 = 10
>>> del var1 # Elimina il riferimento a var1
>>> del var1, var2
# Sintassi generale per eliminare più variabili in una volta
del var1[,var2[,var3[....,varN]]]]
# Operazioni di base con le stringhe
str = 'Hello World!'
print (str)
>>> Hello World!
# Stampiamo il primo carattere di una stringa
print (str[0])
>>> H
# Stampiamo i caratteri dalla terza alla quinta posizione
print (str[2:5])
>>> llo
# Stampiamo una stringa due volte
print (str * 2)
>>> Hello World!Hello World!
# Concateniamo due stringhe
print (str + "TEST")
>>> Hello World!TEST
Operazioni con le Liste e i Dizionari Python
- Liste: probabilmente, la lista è il tipo di dato più versatile e più utilizzato in Python, specialmente quando si opera con grandi quantità di dati. Una lista contiene elementi separati da virgole e racchiusi all’interno di parentesi quadre. Un aspetto interessante delle liste è che i tipi degli elementi all’interno di una stessa lista possono essere diversi. Le stesse operazioni di slice che usavamo per partizionare le stringhe sono applicabili anche alle liste. Anche l’indicizzazione e la concatenazione funzionano come per le stringhe.
- Tuple: una tupla è simile a una lista e consiste in più valori separati da stringhe. Le tuple vengono rappresentate con parentesi tonde e non quadre. Le tuple sono liste a sola lettura e, a differenza del tipo list, non possono essere modificate.
- Dizionari: un dizionario Python è un insieme di coppie chiave-valore che lavora come una tabella hash. Una chiave può essere un qualsiasi tipo Python. I valori, d’altro canto, possono essere un qualsiasi oggetto Python. I dizionari vengono rappresentati da parentesi graffe e l’assegnamento e l’accesso delle variabili avviene usando le parentesi quadre.
# Creiamo delle liste
list = ['abcde', 1234 , 1.032, 'jack', 16.75]
tinylist = [12, 'jo']
# Stampiamo la lista intera
print (list)
>>> ['abcde', 1234 , 1.032, 'jack', 16.75]
# Stampiamo il primo elemento della lista
print (list[0])
>>> abcde
# Stampiamo tutti gli elementi a partire dalla terza posizione
print (list[2:])
>>> 1.032, 'jack', 16.75
# Stampiamo una lista due volte
print (tinylist * 2)
>>> [12, 'jo', 12, 'jo']
# Concateniamo le liste
print (list + tinylist)
>>> ['abcde', 1234, 1.023, 'jack', 16.75, 12, 'jo']
# Creiamo delle tuple
tuple = ('abcde', 1234 , 1.032, 'jack', 16.75)
tinytuple = (12, 'jo')
# Stampiamo la tupla
print (tuple)
>>> ('abcde', 1234 , 1.032, 'jack', 16.75)
# Stampiamo una parte della tupla
print (tuple[1:3])
>>> (1234 , 1.032)
# Moltiplichiamo una tupla
print (tinytuple * 2)
>>> (12, ‘jo’, 12, ‘jo’)
# Implementiamo un dizionario
dict = {}
dict['one'] = "This is dictionary one sample"
dict[2] = "This is sample output two"
tinydict = {'name': 'jack','code':1234, 'department': 'finance'}
print (dict['one']) # Stampa il valore della chiave “one"
>>> This is dictionary one sample
print (dict[2]) # Stampa il valore della chiave “2”
>>> This is sample output two
print (tinydict.keys()) # Stampa le chiavi del dizionario
>>> ['department', 'code', 'name']
print (tinydict.values()) # Stampa i valori del dizionario
>>> ['finance', 1234, 'jack']
Funzioni e cicli in Python
Python include numerose funzioni e pacchetti di supporto all’esecuzione di diversi task. Tuttavia, se dovesse servire una funzione che non è presente in nessuna delle librerie esistenti, sarebbe sempre possibile creare funzioni definite dall’utente. Una funzione è un qualsiasi blocco di codice riutilizzabile e si riconosce dalla parola chiave “def”. Le funzioni parametrizzate sono invece quelle funzioni che prendono delle variabili come parametri di input. Le funzioni definite dall’utente ammettono l’esistenza di uno o più parametri o anche di un numero di parametri non noto.
- Argomento **kwarg: si possono definire delle funzioni con un parametro prefissato
**. Questo parametro inizializza un nuovo valore durante la chiamata della funzione.
- Parametro di default: durante la dichiarazione di una funzione, si può fornire un valore di default per ogni variabile definita all’interno della funzione.
- Funzioni
lambda: la parola chiave lambda si usa per creare funzioni anonime in Python. Una funzione di questo tipo può avere più argomenti e durante la sua esecuzione viene implementata l’espressione dopo il simbolo :.
I cicli in Python
Sia il ciclo for che il ciclo while sono ideati per ripetere più volte l’esecuzione di un blocco di codice. La differenza principale tra i due è che nel for si conosce il numero di iterazioni. Il ciclo while, invece, continua finché non viene soddisfatta una certa condizione. Vediamoli entrambi nel dettaglio, nella seguente implementazione.
# Creiamo una funzione parametrizzata
def greetings(name):
print ('Howdy ', name)
# chiamata della funzione con un argomento
>>> greetings('Smith')
>>> Howdy Smith
# Stessa funzione con un numero non noto di argomenti
def greetings (*names):
print ('Howdy ', names[0], ', ', names[1], ', ', names[3])
# chiamata della funzione con tre argomenti
>>> greet('Emily', 'Smith', 'Rowe')
>>> Howdy Emily, Smith and Row
# Implementazione dell’argomento **kwargs
def greetings(**personDet):
print('Hello ', personDet['firstname'], personDet['lastname']
>>> greet(firstname='Smith', lastname='Emily')
Hello Smith Emily
>>> greet(firstname='Bill', lastname='Keeper', age=75)
Hello Bill Keeper
# Implementazione di una funzione lambda
(lambda x: x*x)(5)
>>> 25
# Implementazione del ciclo While
number=0 counter=0
sum=0
while number >= 0:
number = int(input('enter a digit '))
if number >= 0:
counter = counter + 1
sum = sum + number
avg = sum/counter
print('Total numbers are: ', counter, ', Average is: ', avg)
>>> enter a digit: 10
>>> enter a digit: 20
>>> enter a digit: 30
>>> enter a digit: –1
>>> Total numbers are: 3, Average is: 20.0
# Implementazione del ciclo For
for i in range(1, 5):
if i > 3:
# si usa la keyword continue per saltare l’esecuzione e passare all’iterazione successiva
continue
print(i)
>>> 1
>>> 2
>>> 3
# Ciclo While con condizione Else
number = 0
while number < 3:
number += 1
print('number = ', number)
else:
print('else block is getting executed')
>>> number = 1
>>> number = 2
>>> number = 3
>>> else block is getting executed
Elaborazione dei file e gestione delle eccezioni
Negli ultimi anni, processare i file è una delle funzionalità più importanti di un linguaggio di programmazione. Da quando i dati sono diventati accessibili attraverso più dispositivi persino nelle dimensioni di Terabyte non è possibile analizzarli se non archiviandoli in una memoria esterna. L’elaborazione dei file diventa utile nelle situazioni in cui porzioni di un file devono essere consultate e rese disponibili agli utenti per ulteriori analisi. Python consente di mappare file fisici in file oggetto tramite la funzione open().
file object = open(file name[, access mode][, buffersize])
In questo metodo il primo parametro è adoperato per il nome del file, inclusa la path locale o globale. Il parametro di modalità di accesso è opzionale e definisce il fine per cui sarà aperto un file come read, write, append e altro. ‘w’ viene adoperato per scrivere e ‘r’ per leggere dal file. Esiste anche un parametro opzionale che indica la dimensione del buffer, può essere specificato con valore 0 per rappresentare l’assenza di buffer, con valore 1 per un buffer lineare oppure con altri valori positivi in modo da indicare una specifica dimensione.
Alcune operazioni importanti sui file:
File.close() – metodo usato per chiudere un file salvando il suo stato corrente;File.flush() – effettua il flush del buffer del file;Next(file) – questo metodo itera sul file e ritorna la prossima riga;File.readlines() – legge il file intero. (readline invece legge solo fino a un carattere new-line);File.read([size]) – legge dal file solo la dimensione in byte specificata;File.tell() – ritorna la posizione all’interno del file della riga corrente;File.seek() – serve a leggere o scrivere sul file in una posizione specifica.
# Aprire e scrivere su un file locale
f=open("C:\mytestfile.txt","w")
f.write("Hello! This is a sample text.")
f.close()
# Aprire un file e scrivere una stringa. Dobbiamo fare attenzione a inserire il carattere di new–line “\n”
lines=["Hello world.\n", "This is a string sample.\n"]
f=open("D:\mytestfile.txt","w")
f.writelines(lines)
f.close()
# Leggere da un file fino al carattere di next line
f=open("mytestfile.txt","r")
line=f.readline()
print(line)
f.close()
# Leggere un intero file usando il ciclo While
f=open("C:\mytestfile.txt","r")
line=f.readline()
while line!='':
print(line)
line=f.readline()
# Usare un iteratore per leggere un file (legge finché non trova StopIteration)
f=open("C:\mytestfile.txt","r")
while True:
try:
line=next(f)
print (line)
except StopIteration:
break
f.close()
# Usare la funzione seek e r+ per leggere un file in una data posizione
f=open("D:\mytestfile.txt","r+")
f.seek(6,0)
lines=f.readlines()
for line in lines:
print(line)
f.close()
Gestione delle eccezioni
Talvolta possono verificarsi delle eccezioni che esulano dal normale comportamento di un programma, ad esempio un utente potrebbe fornire un input errato oppure può verificarsi il malfunzionamento di un dispositivo in relazione con l’esecuzione. Gli eventi che, appunto, potenzialmente conducono il programma a non funzionare come previsto possono essere molteplici. La gestione delle eccezioni è un meccanismo adottato per prevenire la chiusura improvvisa di un programma che consente di veicolare verso l’utente messaggi quando viene riscontrato un errore. Python adopera le parole chiave try, except, else e finally per implementare la gestione delle eccezioni.
try: è un blocco ideato per eseguire codice e gestire gli errori durante l’esecuzione;except: se tutte le istruzioni nel blocco try vengono eseguite correttamente, il blocco except non viene eseguito. Se invece avviene un errore all’interno del try;else: se viene specificato un blocco else e non ci sono errori nel try, allora il flusso di esecuzione arriva all’else;finally: il codice nel finally viene sempre eseguito, che sia o meno stata catturata un’eccezione.
# Scriviamo un codice per un blocco try–except
try:
print("this is the try block")
x=int(input('Enter a numeric value: '))
y=int(input('Enter another integer: '))
z=x/y
except ZeroDivisionError:
print("this is the ZeroDivisionError exception block")
print("Division by 0 is not recognized")
else:
print("inside the else block")
print("Division result = ", z)
finally:
print("inside the finally block")
x=0
y=0
print ("printing outside of the try, except, else and finally blocks." )
# Sequenze di output
>>> this is the try block
>>> Enter a numeric value: 20
>>> Enter another integer: 5
>>> inside the else block
>>> Division result = 4.0
>>> inside the finally block
>>> printing outside of the try, except, else and finally blocks.
# Sequenze di output quando si verifica un errore
>>> this is the try block
>>> Enter a numeric value: 30
>>> Enter another integer: 0
>>> this is the ZeroDivisionError exception block
>>> Division by 0 is not recognized
>>> inside the finally block
>>> printing outside of the try, except, else and finally blocks.
Analisi del modulo Statistics di Python
Il modulo Statistics di Python include funzioni per svolgere operazioni matematiche. Discuteremo ora le principali funzioni per il calcolo della media e della dispersione:
| Funzione |
Descrizione |
mean()
|
dato un insieme di dati ne calcola la media |
fmean()
|
calcola la media aritmetica in virgola mobile, è più veloce del precedente |
geometric_mean()
|
calcola la media geometrica |
harmonic_mean()
|
calcola la media armonica |
median()
|
calcola la mediana dei punti |
mode()
|
calcola la moda |
multimode()
|
ritorna una lista dei valori discreti o nominali più comuni |
quantiles()
|
divide i dati in intervalli uguali in base alla probabilità |
stdev()
pstdev()
|
calcola la deviazione standard di un campione o di una popolazione; |
pvariance()
variance()
|
calcola la varianza di un campione o di una popolazione |
# Importiamo il modulo di statistica
import statistics
numbers_list = [1,4,5,6,7,32,22,15,4,66]
print(statistics.mean(numbers_list))
>>> 16.2
print(statistics.median(numbers_list))
>>> 6.5
print(statistics.mode(numbers_list))
>>> 4
print(statistics.stdev(numbers_list))
>>> 20.021099980881278
print(statistics.variance(numbers_list))
>>> 400.8444444444444
print(statistics.fmean(numbers_list))
>>> 16.2
# Eseguiamo le funzioni su una lista mista
numbers_list = [6.75, 33, 2.22, 54, 12.23, 33, 45]
print(statistics.geometric_mean(numbers_list))
>>> 17.41072136913146
print(statistics.harmonic_mean(numbers_list))
>>> 8.954709714991052
print(statistics.multimode(numbers_list))
>>> [33]
print(statistics.quantiles(numbers_list))
>>> [6.75, 33.0, 45.0]
Conoscenza e Intelligenza Artificiale
L’intelligenza artificiale e il Machine Learning sono una combinazione di matematica e programmazione. Negli ultimi due capitoli ci siamo concentrati sulle basi di questi due concetti. Tutti i problemi di intelligenza artificiale possono essere generalmente divisi in due categorie, problemi di Ricerca e problemi di Rappresentazione. Così nascono i modelli, le regole, i frame, le logiche e le reti.
In generale questi algoritmi si muovono intorno al calcolo o alla minimizzazione di distanze, al calcolo di similarità, alla ricerca di soluzioni per equazioni e ad altri concetti matematici. Per implementare proprio questi concetti in termini che possano essere compresi da un processore adoperiamo il codice. In questo caso Python rappresenta il filo d’Arianna tra la matematica e le applicazioni intelligenti.
Test Unit del codice Python
Il Test Unit per programmi è concepito al fine di aiutare i programmatori a gestire potenziali problemi che gli utenti potrebbero riscontrare in futuro. La metodologia di testare singole funzionalità una per volta è conosciuta come Unit Testing e viene generalmente effettuata per ogni funzionalità del programma.
I test possono essere eseguiti usando moduli come unittest, pytest o nose2, che fanno parte delle librerie Python. Se non si vuole far uso di queste librerie è possibile adoperare l’istruzione assert per verificare l’output di un test unit. Vediamo alcuni esempi:
# Questo è un test per la funzione sum() di Python
assert sum([2, 4, 5]) == 11, "Should be 11"
>>> Non ritorna nessun output se l’asserzione è corretta.
# Quando l’asserzione non è vera, ritorna un messaggio d’errore
assert sum([2, 2, 1]) == 6, "Should be 6"
>>> Traceback (most recent call last): AssertionError: Should be 6
# Per eseguire più test contemporaneamente con diversi input, possiamo creare un file .py ed eseguirlo da riga di comando
def testing_sum():
assert sum([2, 2, 3]) == 7, "Sum should be 7"
if __name__ == "__main__":
testing_sum()
print("All tests passed")
# Eseguiamo su shell Windows
$ python test_sum.py
>>> All tests passed
# Usiamo il modulo unittest di Python per eseguire i testi
import unittest
class Testing_Sum(unittest.TestCase):
def testing_sum(self):
self.assertEqual(sum([2, 2, 3]), 7, "Sum should be 7")
def testing_sum_two(self):
self.assertEqual(sum((2, 2, 2)), 5, "Sum should be 5")
if __name__ == '__main__':
unittest.main()
# Eseguiamo su shell Windows
$ python test_sum_unittest.py
.F
======================================================================
FAIL: test_sum_tuple (__main__.TestingSum)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_sum_unittest.py", line 9, in test_sum_tuple
self.assertEqual(sum((2, 2, 2)), 5, "Sum Should be 5")
AssertionError: Sum should be 5
----------------------------------------------------------------------
Ran 2 tests in 0.002s
FAILED (failures=1)
Si può usare il metodo precedente per eseguire un qualsiasi test su Python, semplicemente cambiando il nome della funzione “sum()” col nome della funzione che si desidera testare. Devono essere presenti anche gli argomenti della funzione e un risultato atteso. I test avranno successo qualora si otterranno i risultati attesi, altrimenti falliranno.
Altri capitoli prossimamente in arrivo
- Teoria del Machine Learning e dell’Intelligenza Artificiale;
- classificazione di dati in Python;
- algoritmi per il Machine Learning.