Introduzione
Nei capitoli precedenti, abbiamo discusso le basi della programmazione in Python e l’importanza della matematica nell’implementare modelli di Intelligenza Artificiale (IA). La programmazione e la matematica sono due concetti correlati che costituiscono il fulcro per la realizzazione di teorie di IA come il Machine Learning (ML) e la Data Science.
L’apprendimento si definisce come l’acquisizione di conoscenze e competenze con la pratica, cioè imparare facendo esperienza. Il Machine Learning, o apprendimento automatico, è il paradigma che implementa quest’idea di apprendimento, attraverso lo studio degli input e la comprensione dei dati.
Il Machine Learning, uno dei rami dell’Intelligenza Artificiale, è un campo dell’informatica che rende i sistemi software capaci di apprendere. L’obiettivo di tale apprendimento è quello di migliorare la qualità dei dati esistenti senza necessariamente produrre risultati espliciti. In sostanza, l’enfasi del machine learning è nell’assistere i sistemi ad apprendere nuove informazioni da insiemi di dati di input senza il supporto umano.
Così come la mente umana, anche i sistemi informatici hanno bisogno di informazioni per implementare questa forma di apprendimento. Per fornire i dati necessari si passa attraverso delle fasi dette di Data Observation e Data Preparation. Durante queste fasi, i sistemi vengono esposti a grandi quantità di dati che sono di supporto al processo di apprendimento. I sistemi, facendo esperienza di questi dati, riescono a ottenere una certa comprensione dei loro schemi e del loro significato. Questo, a sua volta, è di supporto alla generazione delle analisi e delle previsioni che vogliamo avere come risultato.
Il Machine Learning e le sue varie forme
Gli algoritmi di Machine Learning si basano sulla tipologia di input che ricevono e sul tipo di calcolo che eseguono per apprendere dall’input. In seguito, vedremo i concetti matematici e i dettagli implementativi dei vari metodi, ma per ora diamo un’occhiata all’ampia classificazione di questi algoritmi.
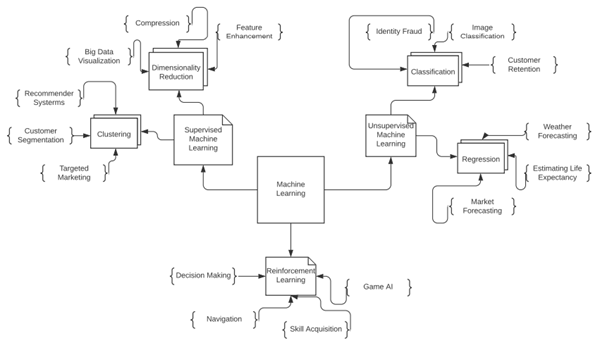
Il Machine Learning si classifica in tre categorie principali: Supervisionato, Non-Supervisionato e Reinforcement Learning. L’immagine sopra mostra le differenze tra queste tipologie di algoritmi e i loro usi.
Machine Learning Supervisionato
Gli algoritmi che lavorano su dati etichettati sono detti algoritmi di apprendimento supervisionato. Questi sono i metodi maggiormente usati per addestrare modelli e lavorare sui dati. I dati etichettati sono dati per i quali sono disponibili sia le “domande” che le “risposte”. Quello che gli algoritmi supervisionati fanno è osservare gli input e i rispettivi output attesi in modo da apprendere quali risposte corrispondono a quali tipi di dati in ingresso. Apprendendo queste relazioni, l’algoritmo è in grado di predire delle risposte qualora gli venga fornito in input un nuovo dato.
Per comprendere il funzionamento dell’apprendimento supervisionato, supponiamo di avere una variabile di input x e una variabile di output y. Allora abbiamo bisogno di una funzione che mappi l’input nell’output.
Viene usata la funzione Y=f(x) per apprendere il mapping tra input e output.
Ora, l’obiettivo principale è avere una stima di questa funzione in modo che, dato un qualsiasi nuovo dato (x), l’algoritmo predica un output (Y). I problemi di apprendimento supervisionato si dividono principalmente in due classi:
- Classificazione: la classificazione è un problema le cui soluzioni sono tipicamente variabili categoriche. Le variabili categoriche includono output come ad esempio colore, genere, e altro, che rientrano in uno specifico insieme di valori. Gli algoritmi di classificazione scelgono da questo insieme il risultato della classificazione. In questo capitolo tratteremo questo problema nel dettaglio.
- Regressione: un problema di regressione è un problema che ha una soluzione ben definita, come ad esempio il peso di un’auto o l’altezza di un albero. Gli output quindi sono valori numerici.
Esempi di algoritmi tipici dei task di apprendimento supervisionato sono gli Alberi Decisionali, il Random Forest, il Nearest Neighbor (KNN) e la Regressione Logistica.
Machine Learning Non-supervisionato
La differenza principale tra algoritmi supervisionati e non-supervisionati è che questi ultimi non vengono addestrati su dati etichettati. Questo significa che, durante il processo di addestramento, l’algoritmo non è a conoscenza delle risposte. Per questo motivo, quello che generalmente le persone associano al concetto di Intelligenza Artificiale sono proprio gli algoritmi di apprendimento non-supervisionato.
Un’intuizione è la seguente: questi algoritmi non hanno bisogno di risposte giuste o sbagliate. Semplicemente, apprendono modelli e schemi in modo da scoprire informazioni e forme interessanti all’interno dei dati.
Gli algoritmi di Machine Learning non-supervisionato possono essere suddivisi come segue:
- Clustering: i problemi di clustering servono a scoprire raggruppamenti nei dati. I dati in input infatti, in genere, contengono raggruppamenti intrinseci. Ad esempio, i giocatori di calcio possono essere suddivisi in gruppi sulla base dei goal segnati. Un esempio di algoritmo di clustering è il K-means.
- Regole Associative: una soluzione è detta “associazione” quando un algoritmo prova a trovare le regole che connettono diverse porzioni dei dati in input. Ad esempio, trovare i tratti comuni tra i giocatori che segnano goal così come tra quelli che fanno assist. Un esempio è l’algoritmo Apriori.
Apprendimento per Rinforzo
Gli algoritmi di Reinforcement Learning sono ancora poco utilizzati rispetto agli altri citati in precedenza. L’obiettivo dell’apprendimento per rinforzo è quello di addestrare un algoritmo a prendere decisioni autonome. Questo processo decisionale si basa sull’esporre l’algoritmo all’ambiente esterno e si vuole, quindi, che questo apprenda dall’ambiente circostante e comprenda la realtà usando un meccanismo del tipo “prova-e-sbaglia”.
Dal momento che l’algoritmo si basa sull’apprendere dalla propria esperienza, le decisioni tendono a diventare più accurate quanto più questo meccanismo è stato ben progettato, mentre si tende a sbagliare terribilmente in caso contrario. L’estrema varietà degli scenari osservabili rende questi algoritmi poco popolari. Il modello teorico alla base degli algoritmi di reinforcement learning sono i Processi di Markov Decisionali.
Classificazione e Clustering dei dati
La classificazione è un tipo di apprendimento supervisionato, mentre il clustering si usa nell’apprendimento non-supervisionato. L’idea alla base del funzionamento di entrambe le tecniche è di raggruppare insieme i dati simili tra loro. La differenza tra i due risiede invece nel fatto che la classificazione si applica a dati etichettati, quando cioè l’output atteso è noto, mentre il clustering viene applicato a dati non etichettati.
La classificazione stabilisce le diverse classi a cui appartengono tutti i dati e predice una classe per ogni variabile finita in input. Il clustering, invece, può funzionare anche su insiemi infiniti di punti.
Esistono due tipi di classificazione:
- Binaria: l’output viene raggruppato e classificato in una di due possibili categorie.
- Multi-classe: si assegna un risultato a una tra più classi.
Vediamo alcuni casi d’uso di classificazione:
- determinare se una email ricevuta sia uno spam, in base alla cronologia dei messaggi spam ricevuti;
- identificare diversi segmenti di clientela sulla base dei comportamenti d’acquisto;
- stabilire se un cliente ripagherà un prestito in base alla sua storia creditizia;
- predire se uno studente supererà un esame in base all’analisi delle domande e al percorso accademico.
Clustering o analisi dei cluster
L’analisi dei cluster è un meccanismo non-supervisionato per supportare il processo di determinazione di modelli interessanti all’interno di un insieme di dati. Generalmente, non esistono algoritmi esatti, per cui è sempre buona pratica considerare un certo numero di algoritmi per poi scegliere quello più adatto al problema che si sta affrontando.
Un cluster è spesso definito come un’area ad elevata densità in un dato spazio di input. Esempi di utilizzo del clustering sono:
- l’identificazione di fake news o di articoli spam;
- generare inserzioni personalizzate per gli utenti in base alla loro cronologia di ricerca;
- comprendere il traffico su una pagina web;
- svolgere analisi di fantacalcio e consigliare i giocatori migliori per il team della settimana successiva.
Capire i classificatori in Python
Per costruire un classificatore in Python andremo a usare scikit-learn, libreria tipica per il Machine Learning. Questa libreria contiene alcune funzioni e metodi importanti su cui dobbiamo soffermarci prima di iniziare a implementare il classificatore.
Scikit-Learn è probabilmente la libreria più completa per il machine learning in Python. Contiene metodi per addestrare modelli, svolgere analisi statistiche e visualizzare dati. In questo percorso di apprendimento useremo scikit-learn per implementare diversi algoritmi di ML e IA.
Importare Dataset da Scikit-Learn: la libreria scikit-learn contiene anche numerosi dataset per far pratica con i problemi di machine learning. Si tratta di dataset pubblici disponibili per essere usati localmente. Useremo le istruzioni di import per importare dati da alcuni di questi dataset.
Train-Test-Split: questo metodo viene comunemente usato per dividere array o matrici in insiemi arbitrari che verranno usati per il training e per il test. La dimensione della suddivisione può essere specificata come argomento della funzione. Questa suddivisione assicura che durante il training non venga usato l’intero set di dati, in modo da evitare di incorrere in situazioni di overfitting e underfitting del modello.
# Definizione del metodo train-test-split
# test_size: valore compreso tra 0.0 e 1.0, indica la porzione di dati da inserire nel test set
# train_size: come prima, viene usato come alternativa per specificare la dimensione del training set
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
# Implementazione tramite l’uso di un numpy array
import numpy as np
from sklearn.model_selection import train_test_split
X, y = np.arange(10).reshape((5, 2)), range(5)
X
>>> array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
list(y)
>>> [0, 1, 2, 3, 4]
# Splittiamo i dati usando una dimensione di test del 43%, poi verifichiamo la suddivisione
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.43)
X_train
>>> array([[0, 1], [6, 7], [4, 5]])
y_train
>>> [0, 3, 2]
X_test
>>> array([[8,9], [2,3]])
y_test
>>> [1, 4]
Per padroneggiare la preparazione, la pulitura e la visualizzazione dei dati, continueremo a usare concetti riguardanti le librerie scikit-learn, NumPy, pandas, matplotlib e seaborn. Python è uno dei linguaggi più usati per risolvere problemi di data science proprio grazie all’esistenza di queste librerie. Nella prossima sezione, iniziamo il nostro primo esempio di machine learning.
Algoritmo Naive-Bayes
Si mostra una rappresentazione del funzionamento del Naive-Bayes. In generale tutti gli altri modelli di classificazione e di clustering si basano sullo stesso principio. L’unica differenza sono le operazioni matematiche specifiche.
# Importiamo scikit-learn e il dataset Wisconsin breast cancer e dividiamo le feature dei dati dalle etichette
import sklearn
from sklearn.datasets import load_breast_cancer
data_set = load_breast_cancer()
label_names = data_set['target_names']
labels = data_set['target']
feature_names = data_set['feature_names']
features = data_set['data']
print(label_names)
>>> ['malignant' 'benign']
# esistono due classi di cancro, per cui si tratta di un problema di classificazione binaria
# Stampiamo i dati grezzi e visualizziamo le descrizioni delle colonne usando la funzione .DESCR
print(data_set.data)
>>>
[1.799e+01 1.038e+01 1.228e+02 ... 2.654e-01 4.601e-01 1.189e-01]
[2.057e+01 1.777e+01 1.329e+02 ... 1.860e-01 2.750e-01 8.902e-02]
[1.969e+01 2.125e+01 1.300e+02 ... 2.430e-01 3.613e-01 8.758e-02]
...
[1.660e+01 2.808e+01 1.083e+02 ... 1.418e-01 2.218e-01 7.820e-02]
[2.060e+01 2.933e+01 1.401e+02 ... 2.650e-01 4.087e-01 1.240e-01]
[7.760e+00 2.454e+01 4.792e+01 ... 0.000e+00 2.871e-01 7.039e-02]]
…. Output Truncated
print(data_set.DESCR)
>>>
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
….
…..Output Truncated
# Importiamo pandas e creiamo un dataframe per esplorare i dati
# per leggere il dataframe usiamo i nomi delle colonne nel dataset
import pandas as pd
df = pd.DataFrame(data_set.data, columns=data_set.feature_names)
# aggiungiamo una colonna per l’output e usiamo il metodo info() per visualizzare informazioni generali
df['target'] = data_set.target
df.info()
>>>
RangeIndex: 569 entries, 0 to 568
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
# per visualizzare i primi 5 elementi usiamo
df.head()
# Importiamo la libreria seaborn per visualizzare dei grafici.
# Usiamo un box plot per analizzare la diffusione dei dati rispetto alla colonna target
import seaborn as sns
box_plot = data_set.data
box_target = data_set.target
sns.boxplot(data = box_plot,width=0.6,fliersize=7)
sns.set(rc={'figure.figsize':(2,15)})
>>>
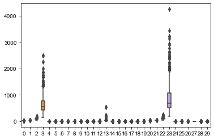
# Siamo quasi arrivati al punto di applicare il Machine Learning sui dati
# Notiamo che ci troviamo di fronte a un problema supervisionato, dal momento che abbiamo etichette dei dati
# creiamo il training set e il test set usando il train-test-split, dopodiché importiamo e istanziamo il classificatore
from sklearn.model_selection import train_test_split
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.33, random_state = 40)
from sklearn.naive_bayes import GaussianNB
g_nb = GaussianNB()
# Usiamo il metodo fit per addestrare il modello su training set
model = g_nb.fit(train, train_labels)
# Chiamiamo il metodo predict sul test set per ottenere l’output della classificazione
predicts = g_nb.predict(test)
print(predicts)
>>> [1 0 1 1 0 1 1 1 0 1 0 1 1 1 0 1 1 1 1 1 1 0 1 0 0 0 0 0 1 1 1 0 0 1 1 1 1
0 1 1 0 1 1 1 0 0 1 1 0 1 0 1 1 1 1 1 0 0 0 1 1 0 1 1 1 0 0 0 1 1 1 0 0 1
0 0 0 1 1 1 1 1 0 1 0 1 0 0 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1
1 0 1 0 1 1 1 1 0 0 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1
1 0 1 0 1 0 1 1 0 1 0 1 0 1 1 1 1 1 1 1 0 1 0 0 1 0 1 0 1 1 1 1 1 1 1 1 1
1 1 0]
# Per valutare il comportamento e la correttezza del classificatore, calcoliamo l’accuratezza
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
>>> 0.9680851063829787
Questo è un esempio basilare dell’implementazione di un classificatore Naive-Bayes con Python. Nel prossimo capitolo, vedremo come effettuare la feature selection e la feature engineering per ottenere una migliore elaborazione dei dati.
Questo capitolo prosegue nella parte seconda.