Service Discovery
Il Service Discovery è un’ulteriore astrazione che permette di definire i metodi di accesso ai Service di Kubernetes. Come già sappiamo, i Service sono oggetti Kubernetes che forniscono dei punti di accesso al cluster dall’esterno e permettono di creare connessioni coi Pod. Quando creiamo un Service per un certo Pod, questo definisce un endpoint identificato da un indirizzo IP, e così per ogni Service. Dal momento che tali indirizzi IP sono dinamici, abbiamo bisogno di un metodo per assegnare degli indirizzi logici ai Service che possano essere sempre validi.
Il Service Discovery è un meccanismo che utilizza un endpoint “centrale” per abilitare gli accessi ai Pod a esso connessi. In sostanza, tale endpoint lavora come una sorta di router, in quanto espone un unico indirizzo IP pubblico per accettare le connessioni e gestisce internamente il networking tra i diversi Pod all’interno del cluster. Le connessioni interne vengono gestite grazie a un DNS interno proprio di Kubernetes, che assegna ai Service degli indirizzi logici come se fossero domini di Internet. Per comprendere meglio il funzionamento generale e l’utilità del Service Discovery possiamo osservare la figura seguente. Con Pod 1 e Pod 2 ci riferiamo a due repliche dello stesso Pod.
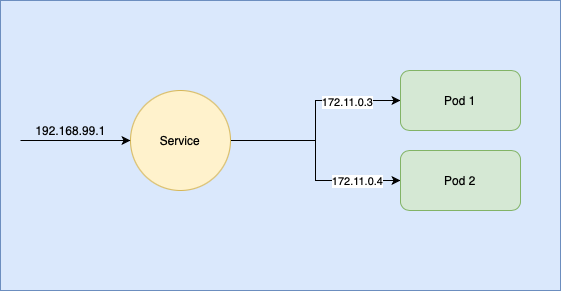
Naming e DNS in Kubernetes
Il DNS di Kubernetes usa una struttura e una nomenclatura nota in modo da assegnare un nome logico all’indirizzo IP di un Service Kubernetes. Quando creiamo un Service, Kubernetes crea anche la entry DNS corrispondente a quel Service. Una forma tipica usata dal DNS di Kubernetes per nominare risorse con un elevato livello di isolamento è:
< my-service-name >.< my-namespace >.svc.cluster.local
Questo nome fungerà da accesso per quei container che sfruttano il servizio
my-service-name e che rientrano nell’ambito del
my-namespace.
I Namespace sono delle astrazioni che servono a dividere gerarchicamente il cluster in parti aventi simili obiettivi oppure simili criteri di accesso. Kubernetes fornisce dei Namespace di default, ma se ne possono specificare altri in base alle esigenze, direttamente all’interno dei Deployment. Esempi di Namespace possono essere “Development”, “Production” e “Sale”, in riferimento a tre tipici processi aziendali.
Per visualizzare i namespace di Default, eseguiamo:
$ kubectl get namespace
Allora il nostro output sarà del tipo:
Output:
NAME STATUS AGE
default Active 11d
ingress-nginx Active 11d
kube-node-lease Active 11d
kube-public Active 11d
kube-system Active 11d
kubernetes-dashboard Active 11d
Ora che abbiamo visto l’utilizzo del DNS interno di Kubernetes, possiamo rivedere la figura precedente in maniera diversa. Supponiamo di volerci connettere a un servizio che chiameremo “myservice” all’interno del namespace “devops”:
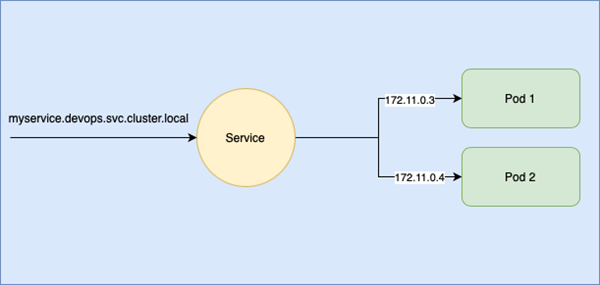
Load Balancing
Kubernetes esegue autonomamente il bilanciamento del carico dei Servizi esposti tramite un Load Balancer. Quando definiamo un Service che funge da endpoint per più repliche di un Pod, otteniamo un unico indirizzo IP di accesso a tale Service. Quando richiediamo una connessione, non sappiamo di preciso a quale delle repliche ci connetteremo, né possiamo specificarlo (e né tantomeno dovrebbe interessarci). Sarà dunque il Service stesso a gestire il bilanciamento del carico tra le repliche, inoltrando la nostra richiesta al primo pod disponibile, o al più libero, qualora fossero tutti già occupati.
Kubernetes fornisce quattro tipi di Service:
- ClusterIP: rende il Service accessibile solo dall’interno del cluster Kubernetes
- NodePort: usa l’IP del nodo come indirizzo statico per accedere al Service dall’esterno
- External Name: assegna al Service un indirizzo DNS personalizzato, configurato ad esempio in una ConfigMap
- LoadBalancer: espone il Service all’esterno del cluster usando il Load Balancer di un cloud provider.
Ora, consideriamo il nostro pod nginx-deployment, definito nel file
deployment.yaml:
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 4
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:9.0
Che, ricordiamo, abbiamo deployato eseguendo:
$ kubectl apply -f ./deployment.yaml
All’interno della directory in cui risiede il file.
Vogliamo quindi creare un Service per questo pod. Allora definiamo un file
my_service.yaml:
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: my-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 96
E applichiamolo eseguendo sempre:
$ kubectl apply -f ./my_service.yaml
All’interno della directory in cui risiede il file. L’output sarà:
Output:
service/my-service created
Settando come
selector il termine
app: nginx, facciamo in modo che il Service sia riferito ai Pod che hanno a loro volta una Label definita come
app: nginx, in questo caso il nostro pod nginx-deployment.
Nel campo
ports abbiamo definito il protocollo di connessione e la porta che il Service userà per effettuare la Service Discovery, cioè TCP. La porta 80 è l’accesso pubblico del Service e ogni richiesta su questa porta verrà reindirizzata sulla porta 96, dove risiete il nostro pod nginx-deployment.
Ora, diamo un’occhiata al service appena creato:
$ kubectl describe service my-service
Output:
Name: my-service
Namespace: default
Labels: app=my-service
Annotations:
Selector: app=nginx
Type: ClusterIP
IP Families:
IP: 10.244.124.255
IPs: 10.107.85.25
Port: 80/TCP
TargetPort: 96/TCP
Endpoints: 172.17.0.3:96,172.17.0.4:96,172.17.0.5:96 + 1 more...
Session Affinity: None
Events:
Come possiamo vedere, l’indirizzo definito nel campo IP costituisce il riferimento al Service all’interno del cluster, mentre gli indirizzi nel campo Endpoints corrispondono agli IP delle repliche del nostro pod che saranno usati dal Service Discovery per reindirizzare le richieste di connessione.
Tuttavia, il nostro Service è del tipo
ClusterIP, per cui non è accessibile dal web, ma è utile ad accettare connessioni interne. Per esporre i Service all’esterno del cluster, di solito si utilizza il tipo
LoadBalancer. In questo modo, verrà montato un Load Balancer su ogni nodo per garantire un corretto bilanciamento del carico. Il Load Balancer non è un componente di Kubernetes, ma è possibile integrarne uno da un cloud provider.
Per esporre i nostri servizi su Jelastic, possiamo settare manualmente un Endpoint nel nostro cluster. Andiamo su
Settings -> Endpoints -> Add. Selezioniamo quindi il nodo desiderato e specifichiamo il nome e la nodePort (Private Port) dell’endpoint. L’IP pubblico e l’URL saranno settati automaticamente da Jelastic. In questo modo Jelastic espone i service dei nodi all’esterno e reindirizza le connessioni ai service di tipo NodePort. Per accedere ai nostri servizi basterà navigare sull’URL fornitoci, che ha il formato
node-env-{env_code}.it1.eur.aruba.jenv-aruba.cloud:{service}:

In fase di sperimentazione, o in caso di applicazioni piccole o temporanee, usare il tipo
NodePort è una buona opzione. Ma, in ambiente di produzione, solitamente i Pod hanno più repliche e quindi abbiamo bisogno di accedere ai servizi tramite un indirizzo unico, che però si riferisce a più repliche di uno stesso Pod. Naturalmente, la replicazione è trasparente e, mentre accediamo a un servizio tramite il suo nome, il load balancer si occupa di inoltrare la richiesta a una delle repliche.
In questo capitolo abbiamo visto come creare i Service Kubernetes per esporre i Pod della nostra applicazione. Abbiamo anche visto come implementare il bilanciamento del carico sul cluster, per automatizzare la gestione del traffico sulle repliche dei Pod. In particolare, abbiamo implementato dei Service di tipo ClusterIP e NodePort su Jelastic Cloud, per abilitare il networking interno e esterno. Nel prossimo capitolo analizzeremo altri metodi per esporre i servizi delle applicazioni Kubernetes.