Introduzione
Finora abbiamo visto come replicare ed esporre le applicazioni grazie ai Service Kubernetes, nel cluster che abbiamo creato sul servizio
CaaS di Aruba, Jelastic Cloud. Abbiamo utilizzato il tipo di service ClusterIP per abilitare le connessioni interne al cluster, e il tipo NodePort per abilitare le connessioni esterne e quindi rendere i nostri servizi accessibili tramite indirizzi IP pubblici. Abbiamo anche visto come, effettuando manualmente lo scaling dei deployment, tramite il tipo NodePort Kubernetes metta direttamente a disposizione un indirizzo IP differente per ogni replica, per cui quest’operazione non è consigliata in ambienti di produzione in cui si usano molti servizi replicati. Infine, abbiamo visto come Kubernetes renda la replicazione trasparente all’utente tramite i meccanismi di Service Discovery e Load Balancing.
Per concludere, vogliamo esaminare l’alternativa ai Service consigliata per le applicazioni su Jelastic Cloud, gli Ingress. In quest’ultimo capitolo, vedremo come creare e usare gli Ingress. Infine, parleremo di AutoScaling, dei suoi vantaggi e di come questo venga implementato in Kubernetes.
Service Discovery e Load Balancing tramite Ingress
Per esporre i servizi del nostro cluster in Aruba, la scelta migliore è usare un oggetto
Ingress, un’astrazione di Kubernetes che supporta connessioni HTTP e HTTPS e che fornisce ai service un indirizzo permanente accessibile dall’esterno e un servizio di bilanciamento del carico. In sostanza, un Ingress è un modo alternativo per effettuare il Service Discovery e il Load Balancing.
Gli ingressi al cluster Kubernetes vengono gestiti da un Ingress Controller, che può essere Traefik, HAProxy oppure Nginix. Una volta specificato l’Ingress, questo doterà i service specificati di un indirizzo IP esterno e di un load balancer.
Un Ingress viene gestito attraverso una serie di specifiche, dette
rules, che definiscono il tipo di connessione e i Service ai quali connettersi. Tutte le richieste in entrata all’Ingress vengono gestite effettuando il matching tra le specifiche dell’Ingress e le specifiche della connessione.
Un esempio di Ingress è definito nel seguente file
my_ingress.yaml:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
labels:
app: my-service
name: my-service
annotations:
kubernetes.io/ingress.class: nginx
ingress.kubernetes.io/secure-backends: "true"
traefik.frontend.rule.type: PathPrefixStrip
spec:
rules:
- http:
paths:
- path: /my-service
backend:
serviceName: my-service
servicePort: 8080
Questo Ingress espone il servizio
my-service associato alla porta 8080 sul path con suffisso
/my-service.
Il nome completo dell’URL sarà
https://${nomeambiente}.${dominio.com}/my-service.
A questo punto eseguiamo il comando:
$ kubectl apply -f ./my_ingress.yaml
Output:
ingress.extensions/my-service created
Ora, visualizziamo l’Ingress appena creato eseguendo:
$ kubectl describe ingress my-service
Output:
Name: my-service
Namespace: default
Address:
Default backend: my-service:80 ()
Rules:
Host Path Backends
---- ---- --------
*
/my-service my-service:80 ()
Annotations: ingress.kubernetes.io/secure-backends: true
kubernetes.io/ingress.class: nginx
traefik.frontend.rule.type: PathPrefixStrip
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CREATE 5s nginx-ingress-controller Ingress default/my-service
L’allocazione dell’indirizzo IP dell’endpoint richiede qualche minuto. Nel frattempo, infatti, l’indirizzo sarà < pending >. In seguito, per visualizzare l’indirizzo IP dell’Ingress, eseguiamo:
$ kubectl get ingress my-service
Output:
NAME CLASS HOSTS ADDRESS PORTS AGE
my-service * 10.244.119.20 80 70m
Alternative
Anche se Jelastic Cloud non supporta ancora il tipo
LoadBalancer, è importante citare e analizzare questa alternativa di Kubernetes che viene usata per esporre servizi replicati. Il tipo LoadBalancer, in sostanza, crea una connessione automatica con l’API del load balancer connesso al cluster Kubernetes, che può essere un qualsiasi LB di un cloud provider. Vedremo che la creazione di questo tipo di servizio non avrà effetti sul nostro cluster in Jelastic Cloud, ma può comunque essere un suggerimento utile per il futuro.
Modifichiamo il solito file
my_service.yaml come segue:
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app: my-service
spec:
selector:
app: nginx
type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 96
Quindi applichiamo le modifiche eseguendo:
$ kubectl apply -f my_service.yaml
Output:
service/my-service configured
Dal momento che al momento Jelastic non supporta il tipo, vedremo che la voce di external-ip è pendente, quindi non possiamo di fatto accedere esternamente al servizio. Infatti, se eseguiamo:
$ kubectl get svc
Abbiamo il campo
EXTERNAL-IP vuoto:
Output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service LoadBalancer 10.107.85.25 80:32399/TCP 32m
AutoScaling e HPA in Kubernetes
L’AutoScaling è la capacità di un cluster cloud di adattarsi automaticamente alle richieste in arrivo ai propri servizi. In precedenza, abbiamo visto
come creare manualmente delle repliche dei pod tramite deployment, tuttavia in pratica uno dei principali vantaggi dell’utilizzo di Kubernetes e del Cloud è proprio la possibilità di fare facilmente autoscaling. Possiamo implementare l’autoscaling sia su Jelastic che tramite Kubernetes.
In particolare, l’HPA (Horizontal Pod Autoscaler) di Kubernetes è un controller che scala automaticamente il numero di repliche di un certo pod adattandosi al traffico e ai requisiti di calcolo, quindi aumenta e riduce il numero di pod in maniera flessibile e questo garantisce l’ottimizzazione dei costi e dell’utilizzazione delle risorse e permette di gestire con successo i picchi di richieste.
In figura vediamo uno schema semplice del funzionamento di HPA.
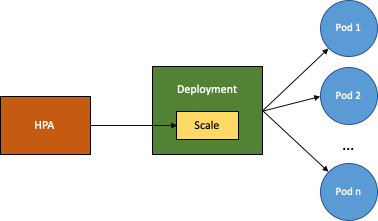
Andiamo quindi a usare HPA sul nostro deployment my-service per implementare l’autoscaling e garantire quindi sempre il funzionamento del servizio. Eseguiamo:
$ kubectl autoscale deployment my-service --cpu-percent=45 --min=1 --max=10
Output:
horizontalpodautoscaler.autoscaling/my-service autoscaled
In questo caso, l’autoscaler aggiungerà una replica quando la percentuale di utilizzo del pod my-service supera il 45%. Successivamente quindi il load balancer interno, tipicamente Nginix (load balancer di default), reindirizza le richieste alle diverse repliche del pod. In particolare, lo scheduling delle connessioni avviene in modo da gestire carichi elevati, per cui cerca di mantenere equilibrato il carico di lavoro sulle repliche. Inoltre, Jelastic alloca dinamicamente la RAM all’interno dei nodi in base ai requisiti e, se la memoria è quasi piena, Jelastic aggiunge un altro nodo al cluster per garantire sempre il servizio. Quando il sistema esce dal picco e torna a regime, l’autoscaler riduce il numero di repliche e Jelastic rimuove i nodi inutilizzati.
Questo tutorial è giunto al termine. Insieme abbiamo esplorato la struttura di Kubernetes e appreso le basi per sviluppare applicazioni distribuite scalabili e affidabili. E questo, è solo l’inizio. In questa serie abbiamo compreso quali sono le potenzialità e possibilità offerte da Kubernetes. Per ampliare ancora le tue skill, consulta le documentazioni ufficiali e continua a seguirci per altri tutorial.